


Understanding the architecture of a Database Management System (DBMS) is crucial for effectively designing, implementing, and managing databases. The DBMS architecture encompasses the fundamental components, their interactions, and the overall structure that enables efficient data storage, retrieval, and manipulation.
In this blog, we will explore the importance of DBMS architecture and its impact on database performance and functionality. We will also discuss the different types of DBMS architecture, including single tier, 2-tier, and 3-tier architectures.
What is DBMS Architecture?

DBMS architecture refers to the structural design and components that work in harmony to manage and maintain databases effectively. One common approach is the client-server architecture, which separates client and server components to facilitate data handling, application logic, and user interactions.
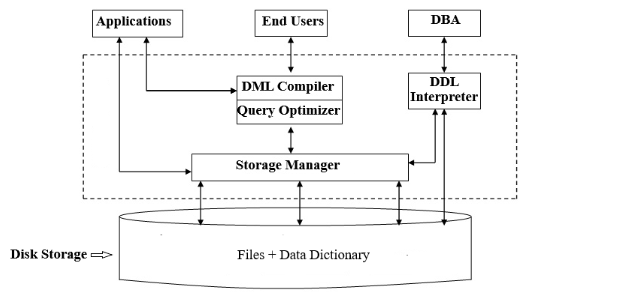
At the core of a DBMS architecture are several key components, including the data dictionary, query processor, transaction manager, and storage manager.
The data dictionary acts as the central repository for metadata, providing information about the database’s structure and organization. The query processor is responsible for interpreting and executing user queries, while the transaction manager ensures data integrity by coordinating and controlling database transactions. The storage manager, on the other hand, is tasked with managing the physical storage of data, including data retrieval, indexing, and buffer management.
These components, along with the communication interfaces and the concurrency control mechanisms, work together to create the relational database architecture.
The 5 Key Components of a DBMS Architecture
DBMS architecture consists of five key functional components that work together to ensure efficient and reliable data management. Let's explore these components in detail:
1. Database Engine:

The database engine is the central component of a DBMS. It is responsible for interpreting and executing user requests, managing data storage and retrieval, and ensuring data integrity and security. It employs various algorithms and data structures to optimize query processing and data access. The database engine also handles concurrent access from multiple users, implementing locking mechanisms to prevent data conflicts. The engine's efficiency directly impacts the overall performance of the database system. It utilizes indexing techniques to speed up data retrieval and employs query optimization strategies to determine the most efficient execution plan for each query. The database engine also manages system resources, such as memory and disk I/O, to maximize throughput and minimize response times.
2. Storage Manager:

The storage manager is responsible for the physical storage of data on the computer's storage devices, such as hard disks or solid-state drives. It handles tasks like file organization, indexing, and buffer management to optimize data access and retrieval.
One of the key functions of the storage manager is to allocate and deallocate disk space as needed. It maintains a free space map, which tracks available storage areas, ensuring efficient use of disk capacity. The storage manager also implements various data access methods, such as sequential, indexed, or hashed, to facilitate quick and efficient data retrieval based on specific query requirements. It also implements mechanisms for data backup and recovery, protecting against data loss due to hardware failures or system crashes.
3. Query Processor:
The query processor is responsible for parsing, optimizing, and executing user queries written in a database query language, such as SQL. It analyzes the query, generates an efficient execution plan, and coordinates the various components to retrieve the requested data.
Once the execution plan is created, the steps that query processor works in is:
- It interacts with the storage engine to access the necessary data. It employs various algorithms to perform operations like filtering, sorting, and joining data from different tables. The processor also manages query concurrency, ensuring that multiple queries can be executed simultaneously without conflicts.
- During execution, the query processor utilizes system resources such as CPU, memory, and I/O operations efficiently. It may employ techniques like parallel processing for large-scale queries to improve performance. The processor also handles error conditions and exceptions that may occur during query execution, providing meaningful feedback to the user.
- After processing, the query processor formats the results according to the user's specifications and returns them to the client application.
4. Transaction Manager:

The transaction manager is responsible for ensuring the ACID (Atomicity, Consistency, Isolation, Durability) properties of database transactions. It manages concurrency control, deadlock detection, and recovery mechanisms to maintain data consistency and integrity in distributed systems. The transaction manager coordinates multiple operations across different resources, such as databases or message queues, to ensure they are treated as a single, indivisible unit of work.
One key function of the transaction manager is to implement locking mechanisms, which prevent concurrent access to the same data by multiple transactions. This helps maintain isolation and consistency. It also employs various concurrency control techniques, such as optimistic or pessimistic locking, to maximize system throughput while preserving data integrity.
In the event of a system failure, the transaction manager plays a crucial role in recovery. It maintains transaction logs that record all changes made during a transaction, allowing the system to roll back incomplete transactions or replay committed ones to restore the database to a consistent state.
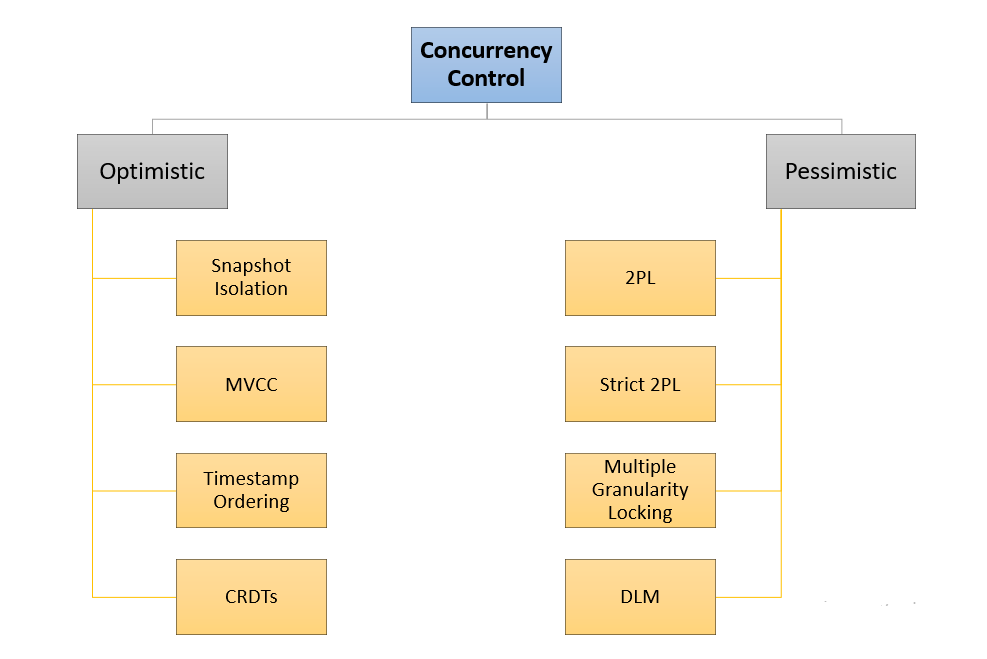
5. Concurrency Control:

The concurrency control component is responsible for managing simultaneous access to the database by multiple users or processes. It ensures that concurrent transactions do not interfere with each other and that data integrity is maintained, even in the face of concurrent operations.
Key mechanisms employed by concurrency control include
- Locking: It prevents multiple transactions from accessing the same data simultaneously
- Timestamping: It assigns unique timestamps to transactions to determine their order of execution
- Multi-version Concurrency Control (MVCC): MVCC allows multiple versions of data to coexist, enabling read operations to proceed without blocking write operations.
The concurrency control component also implements isolation levels, which define the degree to which one transaction must be isolated from the effects of other concurrent transactions. Common isolation levels include
- Read Uncommitted,
- Read Committed,
- Repeatable Read, and
- Serializable, each offering different trade-offs between consistency and performance.
Additionally, this component handles deadlock detection and resolution, ensuring that transactions do not become indefinitely blocked due to circular dependencies on resources. It may employ techniques such as timeout mechanisms or deadlock detection algorithms to identify and resolve such situations, typically by aborting one or more transactions involved in the deadlock.
These five key components work together seamlessly to provide a robust and reliable DBMS architecture, enabling efficient data storage, management, and retrieval for a wide range of applications and use cases.
Types Of Database Models
The three main types of database models are types of dbms architecture:

1 Single-Tier Architecture
1 tier architecture is a database management system design where all components reside on a single server or platform, enabling direct access to the database by end users.
2 Two-Tier Architecture
2 tier architecture is used in client-server applications where multiple users need access to the same database, offering better scalability and security than 1-tier architecture.
3 Three-Tier Architecture
3 tier architecture involves an additional layer between the client and the server. The 3 tier architecture consists of the client communicating with an application server, which then connects to the database system, maintaining isolation between the end-user and the database.
The three-tier model further separates the application logic into a middle tier, distinct from both the client and the database. This middle tier handles tasks such as data processing, business rules, and application workflow, leaving the client to focus solely on the user interface. This separation of concerns offers several advantages such as:
- it enhances scalability, as each tier can be scaled independently based on specific needs.
- it improves maintainability by allowing developers to modify one tier without significantly impacting the others.
The middle tier also acts as a buffer between the client and the database, providing an additional layer of security.
Conclusion
Understanding the core components and architecture of a Database Management System (DBMS) is crucial for effective database design and management. The key elements include the data storage layer, query processor, transaction manager, and access control mechanisms.
By comprehending how the different DBMS modules interact, professionals can make informed decisions during the database development lifecycle.
A strong understanding of DBMS architecture empowers organizations to build scalable, reliable, and adaptable data management solutions that meet their evolving business requirements. This knowledge forms a solid foundation for managing complex database systems and leveraging the full potential of data as a strategic asset.
Frequently Asked Questions FAQs- DBMS Architecture
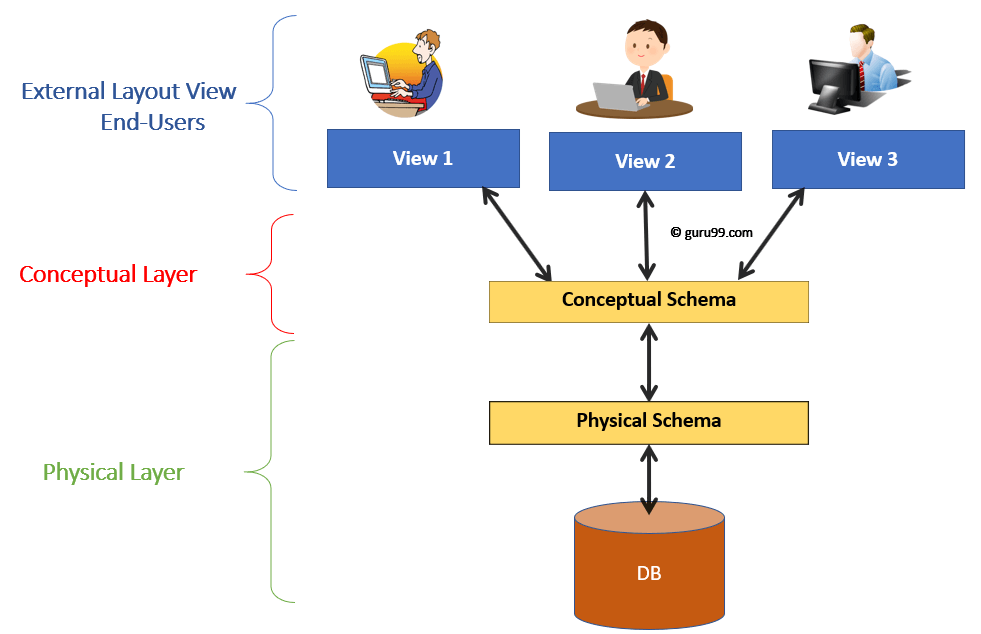
What is external level of a three-level DBMS?
External level is the user view, which provides a customized and personalized perspective of the database. It represents the different ways in which different users access and interact with the database.
What is conceptual level of a three-level DBMS?
Conceptual level is the community view, which provides an abstract data model that represents the overall logical structure of the database. It defines the entities, relationships, and constraints of the database.
What is internal level of a three-level DBMS?
Internal level is the system view, which represents the physical storage details of the database. It defines how the data is actually stored and accessed on the storage media.
What are the three-level architecture abstractions in DBMS?
The three-level architecture abstractions in DBMS are:
- Physical level
- Logical level
- View level








{kind=link}
{kind=link}
{kind=link}
{kind=link}