


Data mining is the process of extracting valuable insights and patterns from large datasets. In today’s data-driven world, the ability to effectively mine and analyze data has become increasingly important for businesses across all industries.
Data mining tools enable organizations to uncover hidden trends, identify customer behaviour patterns, and make more informed decisions. When discussing the best data mining tools, it's essential to consider those that provide insights, streamline workflows, and aid in making informed choices for businesses' data mining needs.
Data analytics plays a crucial role in this process by enabling users to analyze, visualize, and prepare data for analysis, which is vital for generating reports, creating machine learning models, and crafting data visualizations. By understanding the importance of data mining in the modern business landscape, organizations can position themselves for long-term success in an increasingly data-centric environment.
What is Data Mining?
Data mining is the process of extracting valuable insights and patterns from large datasets. It involves using advanced algorithms and statistical techniques to analyze and interpret data in order to uncover hidden relationships, trends, and anomalies.
Various data science platforms and tools are used in data mining, including those for machine learning, deep learning, text mining, predictive analytics, and visualization. The primary goal of data mining is to transform raw data into actionable information that can be used to support decision-making and drive business strategies.
Data mining processes involve techniques, algorithms, and automation to ensure data integrity and usefulness, creating data pipelines for data cleaning, normalization, aggregation, and conversion.
Also, check out Benefits of Data Mining
The Stages of Data Mining Process
1. Data Collection

The data collection stage is a critical step in the data mining process, as it lays the foundation for the entire analysis. During this stage, the relevant data is gathered from various sources, including open-source tools, cleaned, and prepared for further processing.
The key activities involved in the data collection stage include:
Identifying Data Sources: The first step is to identify the relevant data sources that can provide the necessary information for the analysis.
Data Extraction: Once the data sources are identified, the next step is to extract the relevant data. This may involve writing custom scripts, using pre-built data connectors, or even manually downloading data from various sources.
Data Cleaning and Preprocessing: The collected data often contains errors, missing values, or inconsistencies. The data cleaning and preprocessing stage aims to address these issues, ensuring the data is ready for the subsequent stages of the data mining process.
Data Integration: The required data may be scattered across multiple sources. The data integration stage involves combining the data from these different sources into a unified data set, making it ready for analysis.
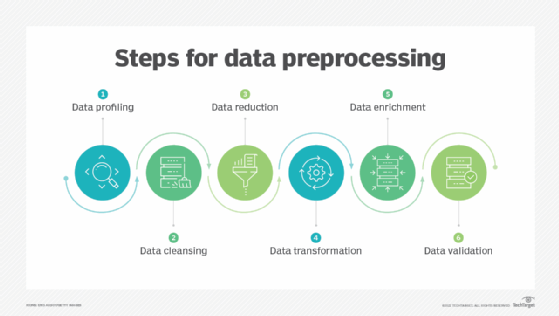
2. Data Preparation and Preprocessing

The data preprocessing phase involves cleaning, transforming, and organizing raw data to ensure it is in a format that data mining algorithms can effectively utilize.
One of the primary goals of data preprocessing is to address any issues or inconsistencies within the data, such as missing values, outliers, or duplicates.
Another important aspect of data preprocessing is data transformation. This may involve scaling or normalizing the data, converting it to a common format, or even creating new features that can enhance the performance of the data mining models.
In addition to cleaning and transforming the data, the preprocessing stage include tasks such as feature selection, where the most relevant and informative variables are identified and retained.
3. Exploratory Data Analysis (EDA)

It is a crucial stage in the data mining process, where data scientists and analysts delve into the dataset to uncover patterns, identify trends, and gain a deeper understanding of the information at hand.
One of the primary goals of EDA is to summarize the main characteristics of the data, such as central tendency, dispersion, and distribution. Techniques like calculating descriptive statistics, creating histograms, and generating scatter plots can help visualize and understand the underlying structure of the data.
Another key aspect of EDA is the identification of outliers and missing values. Analysts use techniques like box plots, z-scores, and clustering algorithms to detect anomalies and handle incomplete data, ensuring the quality and reliability of the dataset.
EDA also involves exploring the relationships between variables, both numerical and categorical. Correlation analysis, cross-tabulation, and visualization tools like scatter plots and heatmaps can uncover the degree and nature of these associations, guiding the selection of appropriate modeling techniques.
4. Model Building

This stage is a crucial component of the data mining process. A graphical user interface can simplify the model-building process by providing integrated visualization tools. This step involves selecting appropriate modeling techniques, training the model, and evaluating its performance.
Some of the key steps and techniques in the model-building stage include:
- Algorithm Selection: Choosing the right algorithm or machine learning model based on the problem at hand, such as regression, classification, clustering, or recommendation systems.
- Hyperparameter Tuning: Adjusting the parameters of the model, such as learning rate, regularization, or the number of hidden layers in a neural network, to optimize its performance.
- Model Training: Using the selected algorithm and tuned hyperparameters to train the model on the available data.
- Model Evaluation: Assessing the model’s performance using appropriate metrics, such as accuracy, precision, recall, or F1-score, to ensure it meets the desired objectives.
- Model Refinement: Iterating on the model by adjusting the algorithm, hyperparameters, or the input data to improve its performance.
5. Model Evaluation
This stage involves assessing the performance and accuracy of the predictive model developed during the modeling phase.
During model evaluation, data miners employ various techniques to measure how well the model fits the data and how accurately it can make predictions. Some common evaluation metrics include accuracy, precision, recall, F1-score, and area under the ROC curve.
6. Deployment
This stage is the final phase of the data mining process, where the developed model is put into production. This stage involves integrating the model into the organization's existing systems and processes, ensuring that the insights generated from the model are effectively utilized.
Real-world Applications Of Data Mining
Some real-world examples of data mining include:
- Customer Analytics: Retailers can use data mining to analyze customer purchasing patterns, preferences, and behavior, allowing them to develop targeted marketing strategies.
- Fraud Detection: Financial institutions can utilize data mining to identify suspicious transactions and patterns, enabling them to prevent and mitigate fraudulent activities more effectively.
- Healthcare Industry: By analyzing patient data, medical professionals can identify risk factors, predict disease outbreaks, and personalize treatment plans, ultimately leading to improved patient outcomes and more efficient resource allocation.
- Urban Planning: By analyzing data from various sources, such as traffic sensors and public transportation records, city planners can optimize infrastructure, reduce congestion, and improve the overall quality of life for citizens.
Top 5 Data Mining Tools
1. Sprinkle Data

When it comes to data mining tools, Sprinkle Data offers a robust solution for businesses of all sizes. It presents a robust data mining solution with a strong focus on user experience and data integration. Businesses looking for a comprehensive data exploration and visualization tool would do well to consider this platform.
Pros:
- It has a user-friendly interface for easy data exploration and analysis
- It has a wide range of data connectors to integrate with various data sources
- Its powerful data visualization capabilities can help to gain meaningful insights
- It also offers Automated data preparation and cleaning functionalities
- It is a highly scalable and secure infrastructure to handle large data volumes
Cons:
- Limited advanced analytical and machine learning capabilities compared to some enterprise-grade platforms
Pricing:
Sprinkle Data offers a tiered pricing model based on the number of active users and data storage requirements. You can contact the sprinkle data team for a customized quote.
2. Tableau
Tableau is a powerful data visualization and analytics tool that has become increasingly popular in the world of data mining.

Pros:
- It has a highly intuitive and user-friendly interface, making it accessible to users of all skill levels
- It has robust data visualization capabilities, allowing users to create stunning and informative dashboards
- Its ability to connect to a wide range of data sources, including databases, spreadsheets, and cloud-based platforms makes it a versatile tool.
- It provides real-time data analysis and interactive dashboards for quick insights
Cons:
- It is more expensive compared to some other data mining tools, especially for enterprise-level users
- It has limited capabilities for advanced statistical analysis and machine learning, which may require additional tools
- It can be resource-intensive, particularly for large datasets or complex visualizations
Pricing:
Tableau offers multiple pricing tiers, ranging from the free Tableau Public version to the enterprise-level Tableau Server or Tableau Online subscriptions
3. RapidMiner

As a comprehensive data mining tool, RapidMiner offers a range of capabilities for businesses and analysts looking to extract valuable insights from their data.
Pros:
- it has an extensive set of data mining and machine learning algorithms
- It has a user-friendly visual interface for easy model-building
- It supports a wide range of data formats and sources
- It is a highly scalable solution for handling large datasets
- Open-source option is available for cost-conscious users
Cons:
- It has a steep learning curve for beginners
- The platform has limited customization options for advanced users
- Some users have reported potential performance issues with large-scale deployments
- Ongoing maintenance and support costs for commercial licenses can be high.
Pricing:
RapidMiner offers both free and paid versions:
- Free: RapidMiner Studio with basic features
- Paid: RapidMiner Studio Pro starting at $5000 per year
- Enterprise solutions with additional features and support available upon request
4. Orange

Orange is a powerful data mining and machine learning tool that offers a wide range of features and capabilities.
Pros:
- It has a user-friendly visual programming interface
- It supports various machine-learning algorithms
- It is an open-source software and is free to use
Cons:
- It has limited support for large-scale datasets
- It has a steep learning curve for beginners
- It has limited customization options compared to other data mining tools
Pricing:
Orange is an open-source tool, so it is free to download and use.
5. IBM SPSS Modeler

It is a powerful data mining tool that provides a wide range of analytical capabilities.The Statistical Analysis System is another robust tool known for its high-level data mining, analysis, and data management capabilities.
Pros:
- It has a user-friendly visual interface for building and deploying models
- It has strong integration capabilities with other IBM analytics products
- It supports a variety of data sources and file formats
- It offers advanced features like text analytics and geospatial modeling
Cons:
- It has a relatively high cost compared to some open-source alternatives
- It has a steep learning curve for new users
- It has limited flexibility in customizing the interface and workflows
- Some users have reported potential performance issues when working with very large datasets
- Licensing can be complex, especially for enterprise-wide deployments
Pricing:
IBM SPSS Modeler is available through an annual subscription model
- Pricing starts at around $500 per user for the base package
- Enterprise-level deployments may require custom pricing quotes from IBM
Conclusion
Businesses and organizations can gain a deeper understanding of their operations, customer behavior, and market dynamics by employing data mining tools.
Whether you’re looking to optimize your marketing campaigns, improve operational efficiency, or uncover new growth opportunities, data mining tools provide the necessary intelligence to navigate the complexities of the modern business landscape.
Using these powerful technologies, you can position your organization for long-term success in an increasingly competitive and data-driven marketplace.
Frequently Asked Questions FAQs- Data Mining Tools
What are data mining tools?
Data mining tools are software programs used to extract, analyze, and visualize data to discover patterns, relationships, and insights.
What are the 5 data mining techniques?
The 5 data mining techniques are:
- Classification
- Clustering
- Regression
- Association rule learning
- Decision trees
What are the four 4 main data mining techniques?
The four main data mining techniques are:
- Predictive modeling
- Cluster analysis
- Association analysis
- Regression analysis
What are the 3 types of data mining?
The three types of data mining are:
- Descriptive data mining
- Predictive data mining
- Prescriptive data mining
What are the 7 steps of data mining?
The 7 steps of data mining are:
- Problem definition
- Data collection
- Data cleaning
- Data transformation
- Data mining
- Pattern evaluation
- Deployment
Is Python a data mining tool?
Python is a programming language that can be used for data mining, but it is not a data mining tool itself.
Is Excel a data mining tool?
Excel is a spreadsheet software that can be used for data analysis, but it is not typically considered a data mining tool.
Is OLAP a data mining tool?
OLAP (Online Analytical Processing) is a technology used for data analysis, but it is not a data mining tool itself.
Is pandas a data mining tool?
Pandas is a Python library used for data manipulation and analysis, but it is not a data mining tool itself.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}