


Recently, there has been a shift in the way businesses approach data management. Earlier, companies relied on centralized data warehouses to store and analyze their data. However, as data volumes have grown exponentially, this model has become increasingly unsustainable.
Enter Data Mesh, a revolutionary approach that decentralized data architecture, data ownership, and management, breaking down data silos and empowering teams to work more collaboratively and efficiently with their data.
In this blog post, we will delve into what data mesh is, how it works, and why it is poised to transform how we think about data in the digital age.
What is Data Mesh and its Benefits?

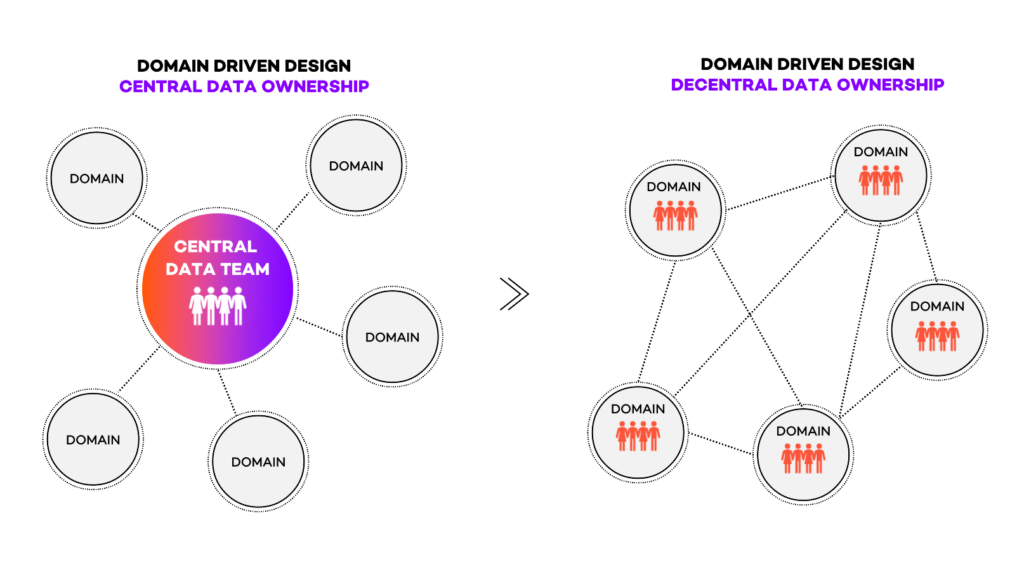
Data mesh is an architectural paradigm that aims to decentralize data ownership and access within an organization. In simple terms, a data mesh breaks down the monolithic data warehouse into smaller, self-contained units called "data products."
Each data product is responsible for one specific domain or business function and is owned and managed by the team closest to that domain. This decentralized approach allows for greater agility and flexibility in managing, storing, and interpreting data.
Some of the key benefits of utilizing a data mesh are:
- Easy Adaptation to Change: Data mesh allows organizations to quickly adapt to changing business requirements by enabling teams to manage their data domains independently.
- Scalability: Organizations can efficiently scale their data infrastructure as required without disrupting existing systems.
- Data becomes accessible to all teams: By making data more accessible across the organization, teams can solely focus on analyzing large datasets.
- Enhanced communication between teams: Data mesh encourages cross-functional collaboration by breaking down traditional silos and fostering communication between different teams.
- Decreased Costs: Organizations can reduce infrastructure costs associated with storing and processing large datasets by eliminating centralized data warehouses or data lakes.
- Helps in Choosing the accurate tools and technologies: Teams can choose the tools and technologies that best suit their specific needs when managing their data domains.
- Helps to improve overall system performance: By distributing workloads across multiple nodes, data mesh can improve overall system performance and reliability.
- Seamless Integration with third-party tools: Data mesh facilitates seamless integration with third-party tools and services through standardized APIs and interfaces.
- Helps to maintain transparency in the process: Data mesh promotes transparency by providing visibility into how different datasets are managed and processed across the organization.
Data Mesh Architecture

Data mesh architecture offers a decentralized strategy for handling data by distributing ownership and control to individual teams responsible for specific business units.
At the core of the data mesh architecture are four key principles:
Domain-driven decentralization:

Instead of centralizing all data operations in a single data warehouse or data lake, data is distributed across multiple domains. Each domain is responsible for defining its schema, storage mechanisms, access controls, and processing pipelines.
Example of E-commerce industry:
In a traditional centralized data system, all customer data, product information, and transaction records would be stored in one central database. However, as the volume of data increases, it becomes increasingly challenging to manage and scale this system.
By implementing a data mesh with domain-driven decentralization, the e-commerce company can break down its data into separate domains such as customer profiles, product catalogs, inventory management, and sales transactions. Each domain is responsible for managing its data and has its own services and APIs to access and manipulate relevant data.
Data as a product:
Data is treated as a first-class citizen within the organization, with clear ownership, accountability, and service-level agreements (SLAs) defined for each dataset. This encourages teams to think of data as a valuable asset that can be shared and reused across the organization.
Example of Data as a Product in a customer analytics team:
The customer analytics team within an organization may have its dedicated domain where it stores customer behavior data. This team treats this data as a product, setting quality standards for how it should be collected, stored, and analyzed. They may also provide APIs or other tools for other teams to access and use this customer behavior data in their analyses.
Self-serve platforms:

To facilitate collaboration and sharing of data assets, organizations should invest in self-service platforms that enable teams to easily discover, access, transform, and analyze datasets without relying on a data platform team.
Example of Sprinkle Data as a self-service data infrastructure
By leveraging self-serve data platform like Sprinkle Data, organizations can empower their teams to make faster, more informed decisions based on real-time insights.
Sprinkle Data is a cloud-based platform that enables organizations to democratize their data by providing self-service analytics capabilities to all users. With Sprinkle Data, teams can easily connect to various data sources, create custom queries, and build interactive dashboards without any coding knowledge.
Federated governance:
While each domain has autonomy over its data operations, there should still be centralized governance mechanisms in place to ensure compliance with regulations, security protocols, and quality standards. This includes establishing common metadata schemas, monitoring tools, and auditing processes.
An example of federated governance within a data mesh model is using the Sprinkle Data embedded analytics feature. Sprinkle data helps in embedding relevant information directly into applications or services, rather than relying on centralized databases or data warehouses.
For instance, a marketing team may need access to customer behavior data to create targeted campaigns. Instead of having to request this information from a central data team, they could simply embed the necessary data points directly into their marketing automation platform.
Steps While Building a Data Mesh
Building a data mesh requires careful planning and execution. In this section, we will go through the steps of building a data mesh.
Step 1: Define your data domain
Data domains are individual units of data that represent specific business functions or processes within an organization. These could be anything from customer information to sales transactions to product inventory.
For example in an e-commerce company. Data domains might include
- customer profiles,
- order histories,
- product catalogs, and
- payment processing.
Each of these domains represents a different aspect of your business that generates its own unique set of data.
Step 2: Identify domain owners
Domain owners are individuals or teams responsible for managing and maintaining the data within their respective domains. They are accountable for ensuring the quality, accuracy, and security of the data they oversee.
For example, in an e-commerce industry
- The customer service team might be responsible for managing the customer profiles domain,
- The finance team will be responsible for handling payment processing.
Each domain owner should have a deep understanding of the business requirements and objectives related to their domain.
Step 3: Implement domain-specific infrastructure
With your data domains and domain owners identified, it's time to implement domain-specific infrastructure. This involves setting up tools, systems, and processes that enable each domain owner to collect, store, process, and analyze their data independently.
For instance,
- The customer service team might use a CRM platform to manage customer profiles
- The finance team uses accounting software for payment processing.
Each domain owner should have access to the resources they need to effectively manage their data without relying on data engineers/data scientists and other IT professionals.
Step 4: Establish communication and collaboration channels
Communication and collaboration are key components of a successful data mesh implementation. To facilitate communication and collaboration among domain owners, consider setting up regular meetings or workshops where teams can discuss challenges and opportunities related to their respective domains.
Step 5: Monitor performance metrics
Lastly, it's important to monitor performance metrics related to your data mesh implementation. By regularly monitoring performance metrics across all domains, you can identify areas for improvement and take proactive measures to address any issues before they escalate.
Data Mesh VS Data Lake VS Data Fabric

Data Mesh:
Data mesh emphasizes decentralizing data ownership and management within an organization. Instead of having a centralized data platform, data mesh supports distributing data responsibilities across various teams or business units where each team is responsible for managing its own data pipelines, storage, and processing.
Data Lake:
A data lake is a central repository that stores all types of raw and unstructured data at scale. It allows organizations to store vast amounts of structured and unstructured data in its native format without needing to pre-define schema or structure.
Data Fabric:
Data fabric is an integration layer that connects disparate sources of data across an organization. It provides a unified view of all the data assets within an organization. Data fabric enables seamless access to data regardless of where it resides (on-premises or in the cloud).
Also, check out: Data Mesh Vs Data Lake
Real-life Use Cases of Data Mesh
- Business intelligence and analytics: Data mesh can help businesses analyze large amounts of data from various sources in real-time to make informed decisions and drive business growth.
- Customer segmentation and personalization: By using data mesh, companies can better segment their customers based on behavior, preferences, and demographics to deliver personalized experiences and targeted marketing campaigns.
- Fraud detection and prevention: Data mesh can be used to detect fraudulent activities by analyzing patterns in data such as transaction history, user behavior, and anomalies.
- Supply chain optimization: Companies can leverage data mesh to optimize their supply chain operations by tracking inventory levels, demand forecasts, transportation routes, and supplier performance.
- Healthcare analytics: Data mesh enables healthcare providers to improve patient care outcomes by analyzing clinical data, treatment effectiveness, disease trends, and patient satisfaction scores.
- Predictive maintenance in manufacturing: Manufacturers can use data mesh to predict equipment failures before they occur by monitoring machine performance metrics, historical maintenance records, and sensor data.
Conclusion:
With the advancement of intricate data ecosystems and the demand for scalable solutions, adopting the principles of data mesh could be the key to unlocking data-driven insights and opportunities in this space of data management.
Frequently Asked Questions FAQs - What is Data Mesh?
What is the data mesh concept?
The data mesh concept is a decentralized approach to managing and organizing data within an organization. It involves breaking down traditional centralized data warehouses into smaller, more manageable units called data domains. Each domain is responsible for its own data quality, access control, and governance, allowing teams to work autonomously while still being able to collaborate and share data with other domains.
What are the 4 principles of data mesh?
The four principles of data mesh are domain-oriented decentralized data ownership and architecture, product thinking applied to data infrastructure, self-serve platform design to create data products, and federated computational governance.
What is a data mesh vs a data lake?
A data mesh differs from a data lake in that a data lake is a centralized repository for storing all types of raw and processed data, while a data mesh is a decentralized approach that focuses on breaking down silos and enabling autonomous teams to manage their domain-specific data.
Is data mesh a tool?
Data mesh is not a tool but rather a set of principles and practices for managing and organizing data within an organization. Organizations can implement these principles using various tools and technologies available in the market.
What is the difference between data mesh and lake house?
A lake house combines the best features of both a traditional data warehouse (consistency) and a data lake (flexibility). In contrast, a data mesh focuses on decentralizing the management of data across different domains within an organization without necessarily requiring consistency across all domains.
Does data mesh replace data lake?
Data mesh does not replace the concept of a data lake but rather complements it by providing a decentralized approach to managing and organizing data within an organization.
What is the difference between Delta Lake and data mesh?
Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and big-data workloads. In contrast, Data Mesh is an architectural paradigm focused on decentralizing the management of organizational-wide datasets across different domains.
What is the difference between data and data lake?
Data refers to raw facts or figures collected about something, while a Data Lake is specifically designed as a central repository for storing structured and unstructured large amounts of raw information for data consumers.
What is the difference between data lake and data platform?
A Data Lake typically serves as part of the larger ecosystem known as the Data Platform which includes multiple components such as databases, ETL tools, analytics tools etc., that help in processing this vast amount of information efficiently.
What is data mesh in DBMS?
In DBMS(Data Base Management System), Data Mesh refers to how organizations distribute responsibility for working with large volumes of diverse information among many people throughout their organization rather than relying solely on specialized roles like database administrators or analysts. This helps in ensuring better collaboration between teams leading to improved decision-making based on accurate insights extracted from complex datasets present in the system.








{kind=link}
{kind=link}
{kind=link}