



A dataset refers to a structured collection of data that is organized in such a way that allows for efficient storage, retrieval, and analysis. Datasets can contain various information, such as numerical data, text, images, or multimedia content, and are commonly used in multiple fields, including scientific research, business analytics, and machine learning.
Datasets are crucial for the data-driven decision-making process, providing the raw material that can be processed, analyzed, and transformed into meaningful insights. The structure and format of a dataset can vary depending on the specific needs and requirements of the business.
Types of Datasets
When working with data, it is crucial to understand the different types of datasets that exist. The primary types of datasets are mentioned below:
1. Numerical Data:

This consists of quantitative information that can be measured and expressed numerically, such as sales figures, temperatures, or ages.
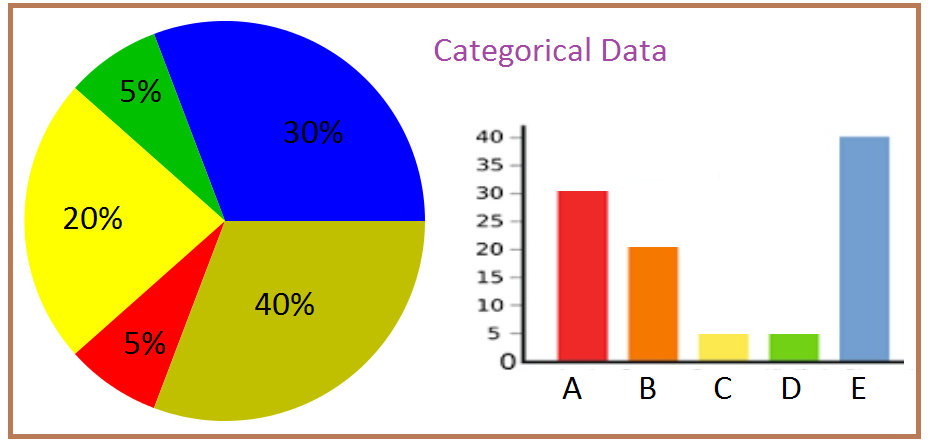
2. Categorical Data:

This data type represents qualities or characteristics that can be grouped into distinct categories, like gender, employment status, or product type.
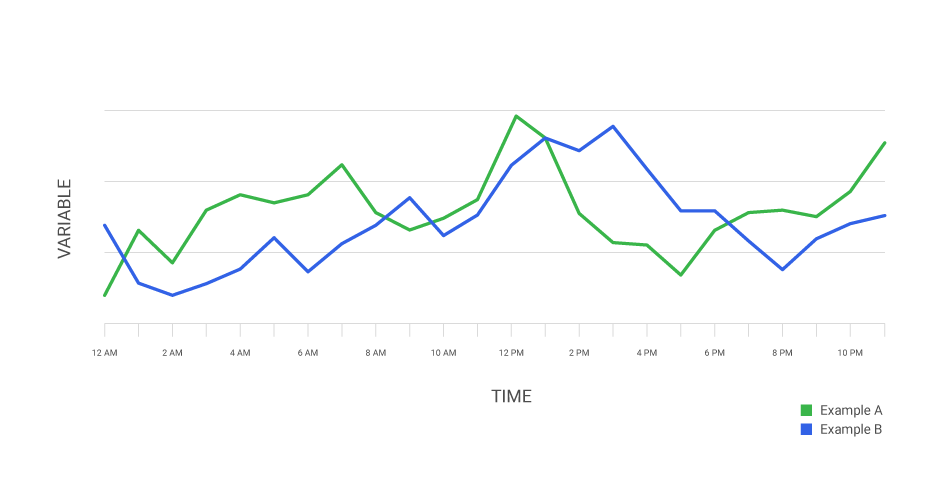
3. Time Series Data:

This dataset tracks values over some time, enabling the analysis of trends, seasonality, and other temporal patterns.
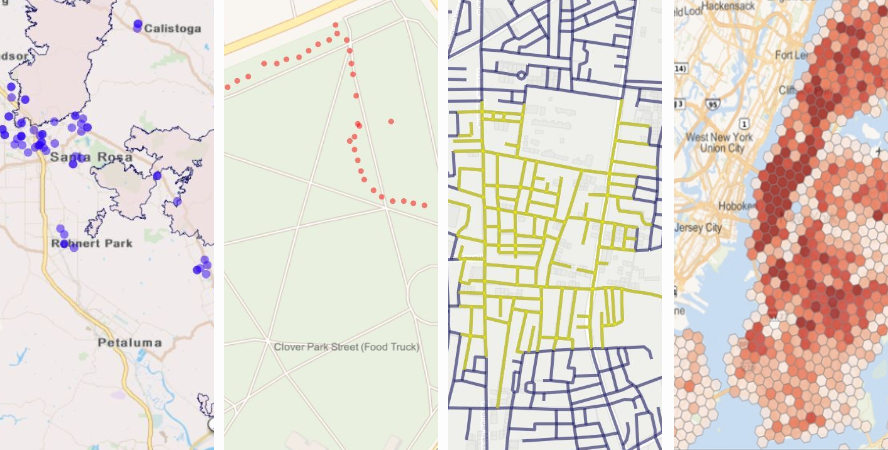
4. Geospatial Data:

This data incorporates location information, such as coordinates or addresses, allowing for spatial analysis and visualization.
5. Text Data:

Unstructured data in the form of written text, like articles, social media posts, or customer reviews, requires specialized extraction and analysis techniques.
The Utilization of Datasets in Real World
Datasets serve as the basis upon which multiple industries and organizations build their insights and strategies. In this section, we will explore several instances that depict the diverse applications of datasets across various disciplines.
Market Research
Businesses often leverage comprehensive consumer datasets to gain a deeper understanding of their target audience's preferences, behaviors, and trends. This information can then be leveraged to inform product development, marketing campaigns, and overall business strategies.
Healthcare Industry
Medical researchers and practitioners utilize extensive datasets comprising patient records, clinical trials, and epidemiological data to identify patterns, develop treatment protocols, and make evidence-based decisions that ultimately improve patient outcomes.
Financial Sector
Investment firms, banks, and financial institutions analyze vast troves of financial data, including stock prices, market trends, and economic indicators, to inform their investment strategies, risk management practices, and regulatory compliance.
Techniques Used to Represent Datasets Statistically
In the field of data analysis, statistical techniques provide a structured approach to summarizing and visualizing complex information, enabling data-driven insights and informed decision-making.
Some of the key statistical techniques used to represent datasets include:
1. Mean
It refers to the arithmetic average of a set of values, calculated by summing all the values and dividing by the total number of observations. It represents the central point around which the data is clustered.
2. Median
It is the middle value when the data is arranged in numerical order. The value separates the higher half from the lower half of the dataset and is less affected by outliers compared to the mean.
3. Mode
It is the value that appears most frequently in the dataset. It represents the most common or typical value within the distribution.
4. Range
It is the difference between the highest and lowest values in the dataset, providing a measure of the spread or variability of the data.
5. Unique value count frequency
It indicates the number of distinct values present in the dataset and the frequency with which each value occurs. This information can be useful in identifying patterns, trends, and potential outliers within the data.
6. Measures of Central Tendency:
These include the mean, median, and mode, which describe the central or typical value within a dataset.
7. Measures of Dispersion:
Statistics such as the standard deviation and variance quantify the spread or variability of the data points around the central tendency.
8. Frequency Distributions:
Histograms, bar charts, and frequency tables illustrate the distribution of values within a dataset, highlighting patterns and outliers.
9. Correlation Analysis:
This technique examines the relationship between two or more variables, measuring the strength and direction of the association.
10. Regression Analysis:
Advanced statistical models, such as linear or logistic regression, enable the prediction of one variable based on the values of others.
Dataset vs Database

Database
A database is a structured system for storing, organizing, and managing large amounts of data. Databases use a relational or non-relational model to store data in a way that allows for efficient retrieval, querying, and manipulation.
Databases are typically managed by a database management system (DBMS), such as
- MySQL,
- PostgreSQL,
- MongoDB,
which provides advanced features for data security, concurrency control, and transaction management.
Dataset
A dataset is a collection of data, typically organized in a tabular format, that is used for analysis, modeling, or training machine learning algorithms.
Datasets are primarily focused on the storage and retrieval of data, with an emphasis on data integrity and consistency. Unlike databases, datasets are generally read-only, meaning that the data within them cannot be directly modified.
Conclusion
In the current period, the role of datasets has become increasingly crucial. Datasets serve as the foundation upon which businesses and researchers build their insights and strategies. As the volume and complexity of data continue to grow, the need for high-quality, well-curated data integration platforms has become paramount. Therefore, using a data integration platform with advanced analytics capabilities can help kickstart your business's analytical needs.
Click here to get started with Sprinkle Data.
Frequently Asked Questions FAQs - What is a data set
What is an example of a dataset?
Examples of datasets include a spreadsheet of sales data, a database of customer information, a collection of images for object recognition, or a set of text documents for natural language processing.
What is a dataset in machine learning?
In machine learning, a dataset is the input data used to train, validate, and test a machine learning model. It consists of features (input variables) and labels or targets (output variables).
What is a dataset in research?
In research, a dataset refers to the data collected and used for a specific study or experiment. Researchers analyze the dataset to draw insights, test hypotheses, and answer research questions.
What is a dataset in Python?
In Python, a dataset is typically represented as a data structure, such as a Pandas DataFrame or a NumPy array, that stores and organizes data for use in various data analysis and machine learning tasks.
What is the purpose of a dataset?
The primary purpose of a dataset is to provide the necessary data for training, evaluating, and deploying machine learning models, as well as for conducting data analysis and research.
What is a dataset for learning AI?
A dataset for learning AI refers to the data used to train and develop artificial intelligence models, such as image datasets for computer vision, text corpora for natural language processing, or sensor data for robotics.
What are the three datasets in machine learning?
The three main datasets in machine learning are:
- Training dataset: Used to train the machine learning model.
- Validation dataset: Used to evaluate the model's performance during training.
- Test dataset: Used to assess the final model's performance on unseen data.
What is a dataset in a neural network?
In the context of neural networks, a dataset refers to the collection of input data and corresponding target outputs (labels) used to train the neural network model.
What is the difference between a model and a dataset?
A model is the learned representation of the patterns and relationships in the data, while a dataset is the raw data used to train, validate, and test the model.
What are the 4 types of data in machine learning?
The four main types of data in machine learning are:
- Numerical (continuous) data
- Categorical (discrete) data
- Ordinal data
- Text data
What are the three main components of a dataset?
The three main components of a dataset are:
- Features (input variables)
- Labels (target variables)
- Instances (data points or observations)








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}