



High-quality data is the foundation for making informed, data-driven decisions. Businesses prioritizing data quality and utilizing all the available data are better equipped to gain meaningful insights, improve operational efficiency, and achieve their strategic objectives.
Accurate, complete, and up-to-date data enables organizations to comprehensively understand their customers, markets, and performance. Poor data quality, on the other hand, can lead to flawed analysis, misguided actions, and suboptimal outcomes.
Maintaining high data standards is essential for transforming raw data into actionable intelligence that supports effective decision-making.
What is Data Normalization and Its Goals?
Data normalization, or database data normalization, is an essential process in database design that aims to arrange data in a database to decrease redundancy, enhance data integrity, and improve the overall efficiency of the database system. This method involves structuring data in a database to minimize duplication and ensure that all data dependencies are logical.
The primary goals of data normalization are to:
- Eliminate redundant data
- Minimize data anomalies
- Simplify database maintenance
- Improve query performance
The process of data normalization typically involves several stages, known as normal forms, which progressively refine the database structure. The most common normal forms are:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce-Codd Normal Form (BCNF)
For example, consider a simple customer database. In an unnormalized table, customer information, such as name, address, and phone number, may be repeated for each order placed by the customer. By applying data normalization, these details would be stored in a separate “Customers” table, with a unique identifier (such as a customer ID) used to link the customer information to their orders in a separate “Orders” table. This reduces data redundancy and ensures data integrity.
In the next section let us discuss the normal forms in detail.
Types of Data Normalisation Forms

There are several types of data normalization, each with its own set of rules and requirements. In this blog section, we will delve into the details of the four main types of data normalization: 1NF, 2NF, 3NF, and BCNF.
First Normal Form (1NF):

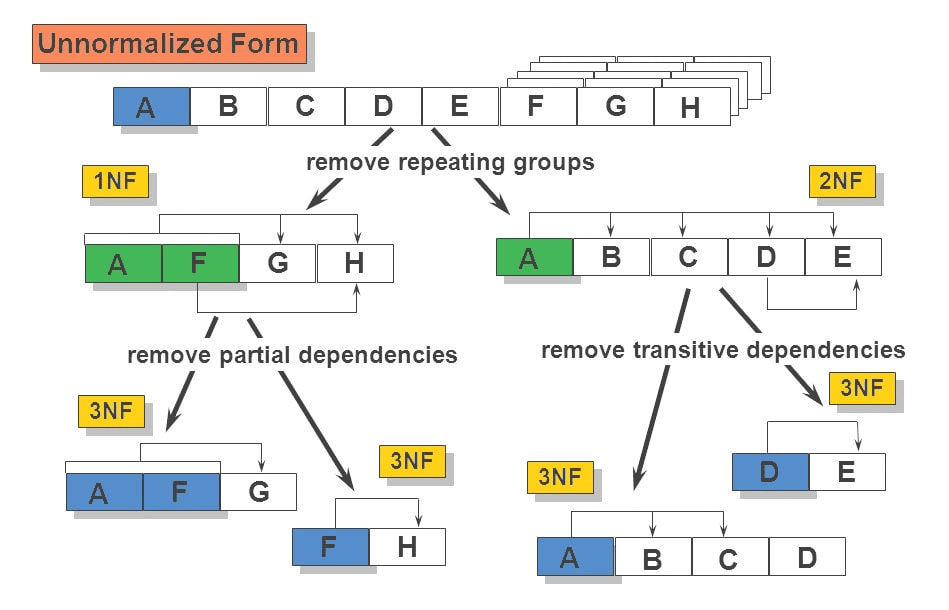
The primary requirement of 1NF is that the data must be stored in a tabular format, with each column containing atomic values. This means that there should be no repeating groups or arrays within a single column. The first normal form mandates that each cell in the table should contain a single value and that values should not be duplicated across multiple rows. This ensures data integrity and eliminates potential issues such as data redundancy, update anomalies, and insertion anomalies.
Adhering to 1NF is a fundamental step in the process of database normalization, which aims to organize data in a structured and efficient manner. It's important to note that while 1NF is a crucial requirement, it is not sufficient on its own to ensure a fully normalized database. Higher normal forms, such as 2NF and 3NF, introduce additional constraints to eliminate certain types of anomalies and dependencies within the data.
Second Normal Form (2NF):

To achieve 2NF, the table must be in 1NF, and all non-key attributes must be fully dependent on the primary key. This means that there should be no partial dependencies, where a non-key attribute depends on only a part of the primary key. To satisfy the requirements of 2NF, the table should not contain any partial dependencies, where a non-key attribute is dependent on a subset of the candidate key rather than the entire candidate key.
In such cases, the table must be decomposed into smaller tables to eliminate partial dependencies and ensure that each non-key attribute is fully functionally dependent on the candidate key. This normalization process helps to reduce redundancy and minimize data anomalies within the database schema. By adhering to the principles of 2NF, the database design becomes more efficient, consistent, and less prone to errors during data manipulation operations.
Third Normal Form (3NF):
In 3NF, the table must be in 2NF, and there should be no transitive dependencies, which helps in eliminating duplicate data. Transitive dependencies occur when a non-key attribute depends on another non-key attribute, which in turn depends on the primary key. In 3NF, all non-key attributes must depend directly on the primary key and not on any other non-key attributes. This eliminates the possibility of partial dependencies, where a non-key attribute is dependent on only a part of the primary key.
By adhering to the principles of 3NF, the table is free from redundancy and update anomalies. Achieving 3NF often involves breaking down a table into smaller, more focused tables, each with its primary key and related attributes.
However, it is essential to strike a balance between normalization and practicality, as excessive normalization can lead to an overly complex database structure and potential performance issues.
Boyce-Codd Normal Form (BCNF):
BCNF is a more stringent version of 3NF, where every determinant (a set of attributes that uniquely identifies a row) must be a candidate key. This means that there should be no partial dependencies or transitive dependencies. In addition to satisfying the 3NF requirements, BCNF (Boyce-Codd Normal Form) ensures that every determinant in the relation is a candidate key. This eliminates any potential for partial dependencies or transitive dependencies, which can lead to redundant data storage and anomalies during data manipulation operations.
To achieve BCNF, a relation must satisfy two additional conditions beyond 3NF:
- Every determinant in the relation must be a candidate key.
- Every non-prime attribute (an attribute that is not part of any candidate key) must be fully functionally dependent on every candidate key.
By adhering to these stricter rules, BCNF guarantees that all attributes in a relation are fully dependent on the primary key, and no attribute is dependent on a non-key attribute. Consequently, relations in BCNF are considered free from any type of anomalies, including insertion, update, and deletion anomalies, ensuring data consistency and efficient data management.
Data Normalisation Techniques in Data Analytics and Machine Learning
Data normalization is a crucial step in data preprocessing for various analytics and machine learning applications. Data normalization is crucial in reducing data input errors, which can occur when changing, adding, or removing system information.
Here are three key data normalization techniques:
1. Min-Max Normalisation:
Also known as feature scaling, this method linearly transforms the data to a common range, typically between 0 and 1. It preserves the relationships between the original data points. This linear transformation is achieved by subtracting the minimum value from each data point and dividing it by the range (maximum value - minimum value). Consequently, all data points are mapped onto a common scale, with the minimum value transformed to 0 and the maximum value transformed to 1.
This process ensures that no single feature dominates the others due to its larger range or magnitude, thereby preventing potential biases during the modeling phase. Normalization is beneficial when dealing with features with vastly different scales or units, as it enables the model to treat all features equally and learn their respective contributions more effectively. However, it is important to note that this technique is sensitive to outliers, as they can significantly impact the minimum and maximum values used for scaling.
Formula:
x_norm = (x - min(x)) / (max(x) - min(x))
2. Z-Score Normalisation:
This technique standardizes the data by subtracting the mean and dividing it by the standard deviation. The resulting values have a mean of 0 and a standard deviation of 1, making the data unitless. This process, known as standardization or z-score normalization, is particularly useful when dealing with features on different scales or units. By transforming the data to have a mean of 0 and a standard deviation of 1, the features are rescaled to a common range, allowing for more meaningful comparisons and preventing any one feature from dominating the analysis due to its larger scale.
This normalization technique can enhance the performance of certain algorithms that assume the input data is normally distributed or centered around zero. However, it is important to note that this transformation is a linear operation and does not account for potential non-linear relationships or outliers within the data. Therefore, it may be combined with other data preprocessing techniques, such as outlier removal or non-linear transformations, to achieve optimal results in various data analysis and modeling tasks.
Formula:
x_norm = (x - mean(x)) / std(x)
3. Decimal Scaling:
In this approach, the data is scaled by moving the decimal point of the values. The number of decimal places moved is based on the magnitude of the maximum absolute value in the data. Furthermore, this scaling technique ensures that all values in the transformed dataset fall within the range of 0 to 1, facilitating more efficient processing and preventing potential computational issues arising from excessively large or small values.
It is a straightforward and widely adopted method for normalizing data, particularly in machine learning and data mining applications where feature scaling is a crucial preprocessing step. However, it is important to note that this approach can be sensitive to outliers, as the presence of extreme values can skew the scaling factor and potentially distort the distribution of the transformed data. In such cases, alternative normalization techniques, such as robust scaling or quantile transformations, may be more appropriate.
Formula:
x_norm = x / 10^j, where j is the smallest integer such that max(|x_norm|)< 1
How Sprinkle Data Can Help With Data Normalisation
Data normalization is a critical process in data management and Sprinkle Data, a leading data integration platform, offers robust solutions to streamline data normalization and enhance your data processing capabilities:
- Sprinkle’s real-time SQL transformation capabilities empower users to perform complex data transformations, including normalization, directly within the platform, facilitating efficient data pipelines. This feature allows for seamless data processing, enabling users to maintain data integrity and consistency across their data sources.
- Sprinkle’s versatile data ingestion capabilities support a wide range of data sources, including databases, SaaS applications, and cloud storage. This comprehensive approach ensures that data from various origins can be efficiently normalized and integrated into a unified data ecosystem.
- Sprinkle’s support for Python notebooks further enhances the data normalization process, providing users with a powerful and flexible environment to customize their data transformation workflows. This integration allows for advanced data manipulation, including complex normalization algorithms, to be executed within the platform.
By leveraging Sprinkle Data’s data normalization features, organizations can achieve a higher level of data quality, improve decision-making, and drive better business outcomes.
Frequently Asked Questions- Normalisation of Data
How do you normalize data?
Normalizing data involves restructuring the data to eliminate redundancy and improve data integrity. This is typically done by breaking down a database into smaller tables and defining relationships between them.
What are the 5 rules of data normalization?
The five rules of data normalization are:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce-Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
What is 1st 2nd and 3rd normalization?
- 1NF: Eliminate repeating groups, and ensure all attributes are atomic.
- 2NF: Eliminate partial dependencies, and ensure full dependency on the primary key.
- 3NF: Eliminate transitive dependencies, and ensure all attributes depend only on the primary key.
What are the first 3 stages of normalization?
The first three stages of normalization are:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
What is the difference between 2NF and 3NF normalization?
The main difference between 2NF and 3NF is that 2NF focuses on eliminating partial dependencies, while 3NF focuses on eliminating transitive dependencies.
What is 3rd normalization in a database?
Third Normal Form (3NF) is a database normalization rule that states that all attributes in a table must be dependent on the primary key, and there should be no transitive dependencies.
What is normalization 1NF 2NF?
1NF: Eliminate repeating groups, and ensure all attributes are atomic. and 2NF: Eliminate partial dependencies, and ensure full dependency on the primary key.
What is first normalization?
First Normal Form (1NF) is the first step in the normalization process. It requires that the data be stored in a tabular format, with each cell containing a single value, and that there are no repeating groups.
What is 2NF in DBMS?
The second Normal Form (2NF) is a database normalization rule that states that all non-key attributes must be fully dependent on the primary key. This means that there should be no partial dependencies.
How to convert 2NF to 3NF?
To convert a database from 2NF to 3NF, you need to eliminate any transitive dependencies. This can be done by creating new tables to hold the transitive dependencies and then establishing relationships between the tables.
What is an example of 3NF?
An example of a Third Normal Form (3NF) is a customer database that has separate tables for customer information, order information, and product information. Each table only contains attributes that are directly dependent on the primary key, and there are no transitive dependencies.








{kind=link}
{kind=link}
{kind=link}