



What is ETL?

ETL, or Extract, Transform, Load, is a data integration process that involves pulling data from various sources, transforming that data into a desired format suitable for data analysis, and then loading the transformed data into a target data repository preferably a data warehouse. This approach is essential to data management and business intelligence applications, enabling organizations to analyze data from disparate sources.
The Three Fundamental Components of ETL
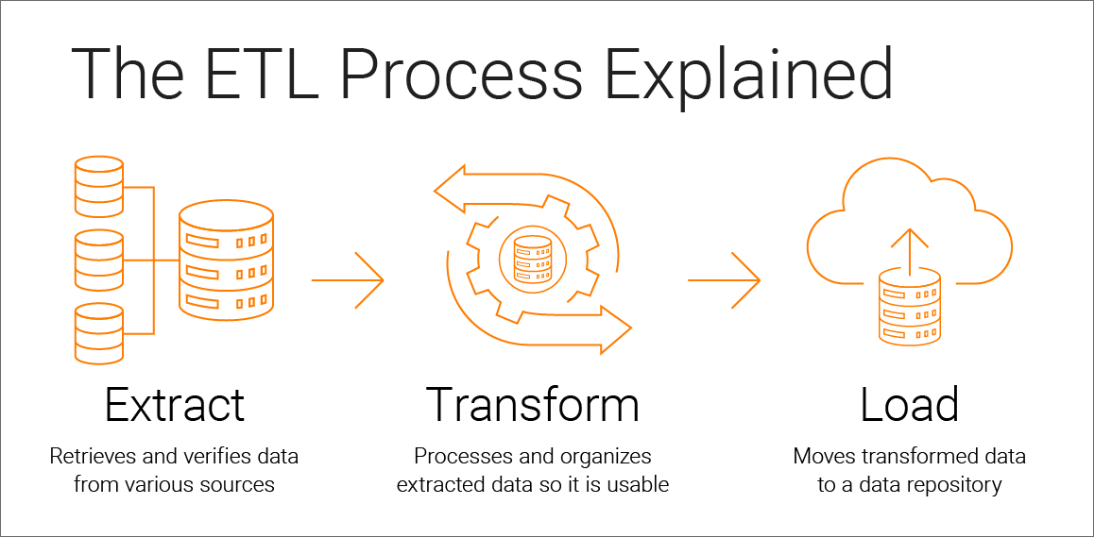
The process of extracting, transforming, and loading data, commonly known as ETL, is a critical component of data integration and business intelligence. This structured approach ensures data quality and consistency across an organization's information systems. Let's examine the three key elements that comprise the ETL workflow:
Extraction Process
The extraction phase involves retrieving data from various source systems, which may include databases, spreadsheets, or other applications.
This step requires identifying the relevant data, understanding its structure, and developing the necessary mechanisms to securely access and extract it.
Transformation Process
Once the data has been extracted, the transformation phase begins. This involves cleansing, standardizing, and enriching the data to align with the target system's requirements.
Transformation can include tasks such as data type conversion, value normalization, and the application of business rules.
The transformation process is critical in ensuring data integrity and consistency across various systems. During this stage:
- Data is cleansed to remove any errors, inconsistencies, or duplicates that may have been introduced during the extraction phase.
- Standardization techniques are then applied to ensure data adheres to predefined formats and conventions, enabling seamless integration and interoperability.
- The transformation phase allows for data enrichment, where additional contextual information or metadata can be appended to the existing data set. This enrichment process enhances the overall value and usability of the data, enabling more comprehensive analysis and decision-making.
Loading Process
The final step in the ETL process is loading the transformed data into the target system, which is typically a data warehouse or database. This phase ensures the data is properly formatted, indexed, and organized to facilitate efficient querying and analysis by end-users. The loading phase is critical as it determines the accessibility and usability of the transformed data for various analytical processes and reporting.
Some considerations to keep in mind during the load data phase:
- Effective indexing and partitioning strategies during the load process can significantly enhance query performance, enabling faster data retrieval and reducing response times for complex analytical workloads.
- The ETL process should incorporate robust error handling and logging mechanisms to ensure data quality and enable auditing and troubleshooting when issues arise.
Regular monitoring and maintenance of the ETL pipeline are also crucial to ensure its continued efficiency and reliability, especially as data volumes and complexity increase over time.
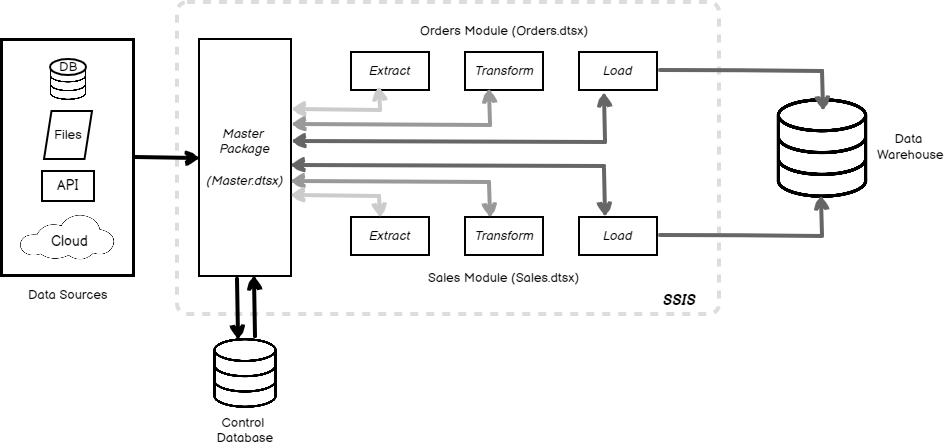
The Three-Tier ETL Architecture: Optimizing Data Transformation Workflows

The foundational structure of an effective ETL (Extract, Transform, Load) process is the three-tier architecture. This strategic approach organizes the data transformation journey into distinct, interconnected layers that streamline operations and enhance data integrity.
The first tier, the Landing Area, serves as the initial reception point for raw, unprocessed data from various sources. This zone provides a secure and structured environment to ingest the data without any transformations applied.
The second tier, the Staging Area, acts as an intermediary zone where the data undergoes necessary cleansing, formatting, and transformation steps. This transitional space allows for complex data manipulations to occur before the information is deemed ready for the final destination.
The third and final tier, the Data Warehouse Area, is the ultimate repository where the transformed, high-quality data is loaded and stored. This area is optimized for efficient data retrieval, analysis, and reporting, enabling organizations to derive valuable insights from their information assets.
Building an Effective ETL Architecture
Constructing a robust ETL architecture is a fundamental step in establishing a reliable data pipeline. This blog section will explore the key considerations and best practices for building an ETL architecture that meets your organization's data management needs.
Data Sources:
Identify and understand the various data sources, both internal and external, that need to be integrated. To effectively analyze and derive insights, it is crucial to have a comprehensive understanding of the available data sources and their characteristics. This includes assessing the quality, reliability, and relevance of each data source, as well as identifying any potential biases or limitations.
Data Transformation:
After assessing the current state of the data, it is crucial to outline a comprehensive data transformation strategy. This should encompass various techniques to enhance data quality and establish consistency across all data sources.
Data cleansing involves identifying and correcting or removing erroneous, incomplete, or duplicate records. Techniques such as data validation, outlier detection, and deduplication should be employed to ensure data integrity.
Data normalization includes converting data into a consistent format, handling missing values, and resolving any discrepancies in data formats or units of measurement. Normalization enhances data interoperability and facilitates seamless integration across different systems or applications.
In addition to the previously mentioned transformation strategies, it may be necessary to perform data aggregation or disaggregation, depending on the desired level of granularity. Data aggregation involves combining related data elements into summarized forms, while disaggregation breaks down aggregated data into more granular components
Data Staging:
Establish a data staging area to temporarily store and prepare data before it is loaded into the target system. This intermediate storage environment serves as a transitional zone where data can be temporarily housed and undergo necessary transformations before being loaded into the target system. It minimizes the risk of corrupting or overwriting existing data in the target environment.
Load Strategies:
Decide on the appropriate load strategies, such as full or incremental loads, to optimize performance and minimize data redundancy. It is crucial to establish a robust data validation process to ensure the accuracy and integrity of the loaded data. This may involve implementing data quality checks, reconciliation procedures, and error-handling mechanisms to identify and resolve any discrepancies or anomalies during the loading process.
Continuous monitoring and optimization can help ensure that the data loading processes remain efficient, scalable, and aligned with the organization's data management objectives.
Scalability and Performance:
As data volumes continue to grow exponentially, it is crucial to architect a system that can handle this growth while maintaining efficient data processing and retrieval.
One approach is to implement a distributed architecture with horizontal scaling capabilities. This can be achieved by leveraging a cluster of nodes, each responsible for processing and storing a portion of the data. To ensure efficient data processing, we can employ techniques such as parallel processing and load balancing.

Parallel processing allows for concurrent execution of tasks across multiple nodes, thereby improving overall throughput. Load balancing distributes the workload evenly among the available nodes, preventing any single node from becoming a bottleneck. For efficient data retrieval, we can implement a distributed caching layer, such as a distributed in-memory cache or a content delivery network (CDN). This layer can store frequently accessed data closer to the end-users, reducing latency and improving response times.
Implementing a data lake or a distributed file system can provide a scalable and fault-tolerant storage solution for large volumes of structured and unstructured data. These systems are designed to handle petabytes of data and offer features like data replication, compression, and efficient data access patterns.
Monitoring and Error Handling:
Implement robust monitoring and error-handling mechanisms to ensure the reliability and resilience of the ETL process. It is crucial to establish comprehensive logging and auditing procedures to facilitate troubleshooting and root cause analysis in the event of any issues or failures.
This involves
- maintaining detailed logs of each step in the ETL process,
- capturing relevant metadata, and
- recording any errors or exceptions encountered.
In addition to monitoring and error handling, it is advisable to implement appropriate data validation and quality checks throughout the ETL pipeline.
Sprinkle Data: Optimizing Your ETL Architecture for Maximum Efficiency

As organizations grapple with the exponential growth of data, the need for robust and scalable Extract, Transform, and Load (ETL) solutions has become increasingly crucial. Sprinkle Data emerges as a powerful platform that streamlines the ETL process, enabling businesses to optimize their data architecture and unlock valuable insights.
One of the primary benefits of Sprinkle Data is its ability to seamlessly integrate with a wide range of data sources, from databases and cloud storage to SaaS applications and APIs. This versatility allows organizations to consolidate their data from disparate sources, ensuring a centralized and cohesive data ecosystem.
Sprinkle Data's automated data transformation capabilities eliminate the need for manual coding, saving valuable time and resources. The platform's scalability is another key advantage, allowing businesses to handle growing data volumes and evolving data requirements without compromising performance or reliability.
Sprinkle Data's comprehensive suite of features and its ability to optimize ETL architecture make it a compelling choice for organizations seeking to streamline their data management processes.
Click here to get started with the platform.
Frequently Asked Questions FAQs- Architecture of ETL
What is the 3-layer architecture of the ETL cycle?
The 3 layer architecture of the ETL cycle consists of:
- Extraction Layer
- Transformation Layer
- Load Layer
What are the 5 steps of the ETL process?
The 5 steps of the ETL process are:
- Extraction
- Cleansing
- Transformation
- Integration
- Loading
What is an ETL diagram?
An ETL diagram is a visual representation of the ETL process, showing the flow of data from the source systems to the target data warehouse or database.
What is the architecture of the ETL tool?
The typical architecture of an ETL tool includes:
- Data Extraction
- Data Transformation
- Data Loading
- Scheduling and Monitoring
What is ETL and its types?
ETL (Extract, Transform, Load) is the process of extracting data from one or more sources, transforming the data to fit operational needs, and loading the data into a target database or data warehouse. ETL types include batch processing and real-time processing.
What is ETL with an example?
An example of ETL is extracting sales data from an e-commerce platform, transforming the data to a standardized format, and loading it into a data warehouse for analysis.
What is the ETL framework?
The ETL framework provides a structured approach to the ETL process, including data mapping, data transformation rules, and the overall workflow.
What is ETL in workflow?
ETL is used in a workflow to automate the process of moving data from source systems to a target data repository, ensuring data quality and consistency.
What is ETL data mapping?
ETL data mapping is the process of mapping the source data fields to the corresponding target data fields, ensuring the data is transformed correctly.
Why is ETL used?
ETL is used to integrate data from multiple sources, clean and transform the data, and load it into a centralized data repository for reporting and analysis.
What is an ETL pattern?
An ETL pattern is a reusable design for implementing a specific ETL functionality, such as slowly changing dimensions or incremental loading.
What is ETL's role?
The ETL role involves designing, implementing, and maintaining the ETL process, ensuring the data is accurately extracted, transformed, and loaded into the target system.
How to create an ETL?
To create an ETL process, you need to define the source and target systems, map the data fields, design the transformation logic, and implement the loading process.
What are the layers of ETL?
The layers of ETL are:
- Extraction Layer
- Transformation Layer
- Load Layer








{kind=link}
{kind=link}