

.png)
This article gives a brief idea about building efficient data pipelines in Sprinkle. A data pipeline should be created in such a way that data is getting updated from ingestion to insights without any failures. There are many options on the auto-run page to make the pipelines robust and also to use the warehouse cost-effectively.
All the options and good practices of pipeline building are explained with the use cases.
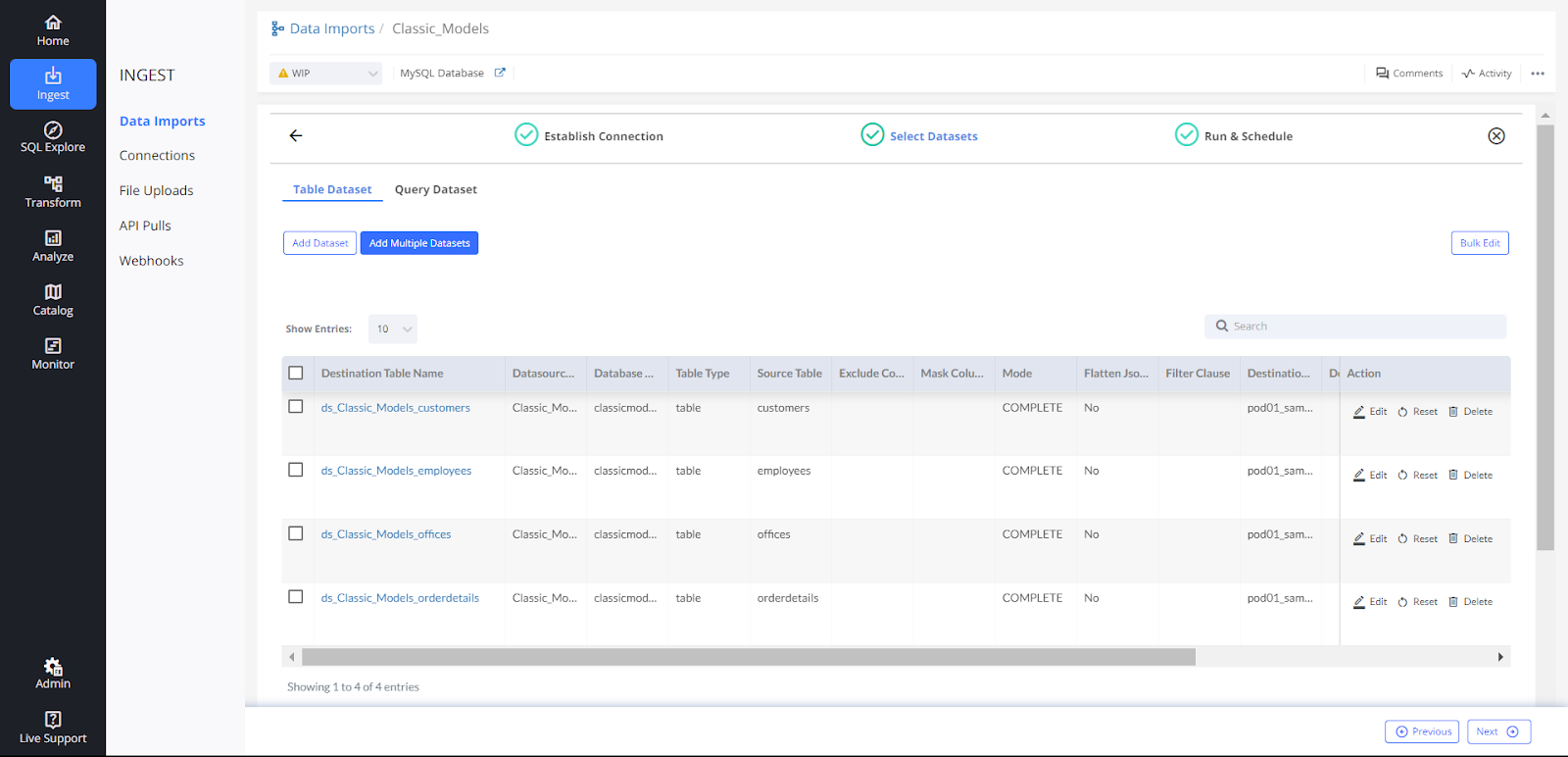
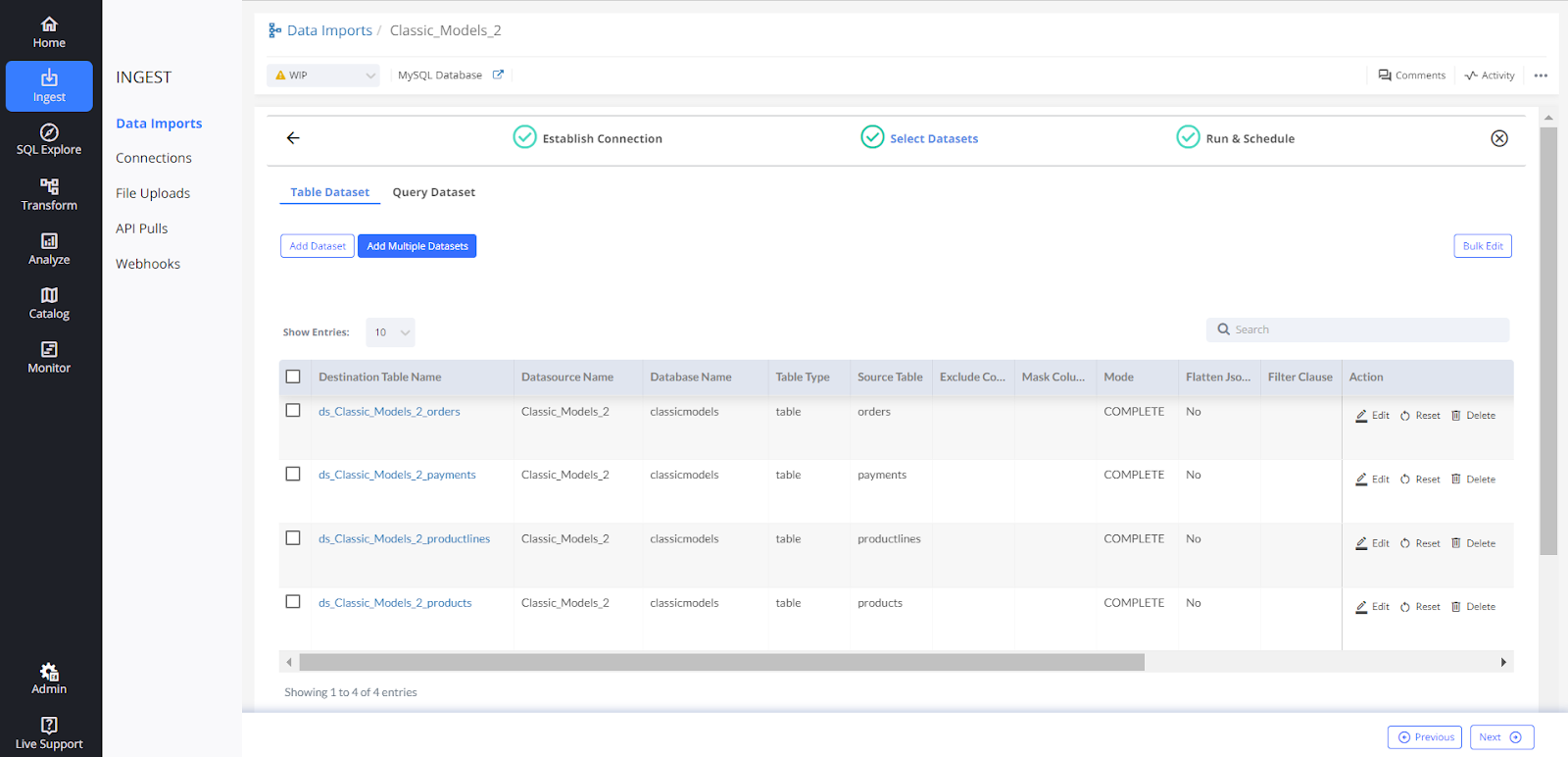
There are 2 data imports with 4 data sets added in each.
1. Data Import 1 → Classic_Models
2. Data Import 2 —> Classic_Models_2
1. Scheduling The Data Import Job (Auto-Run)
1.1) Turn on the Auto-Run button, and select the frequency for scheduling the job. Click on ‘Save'.

1.2) On saving, Sprinkle will automatically populate all the tables in the Ouputs section that are getting created from this data import.
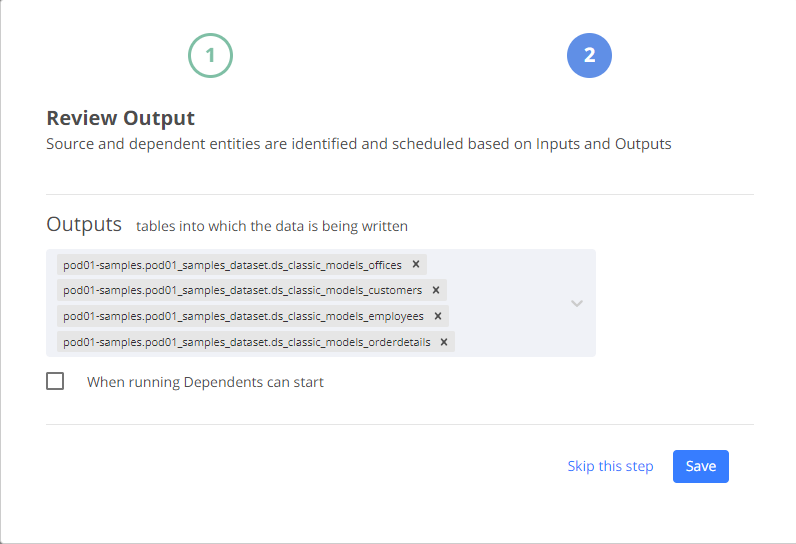
1.3) Post saving the Data Import is scheduled.
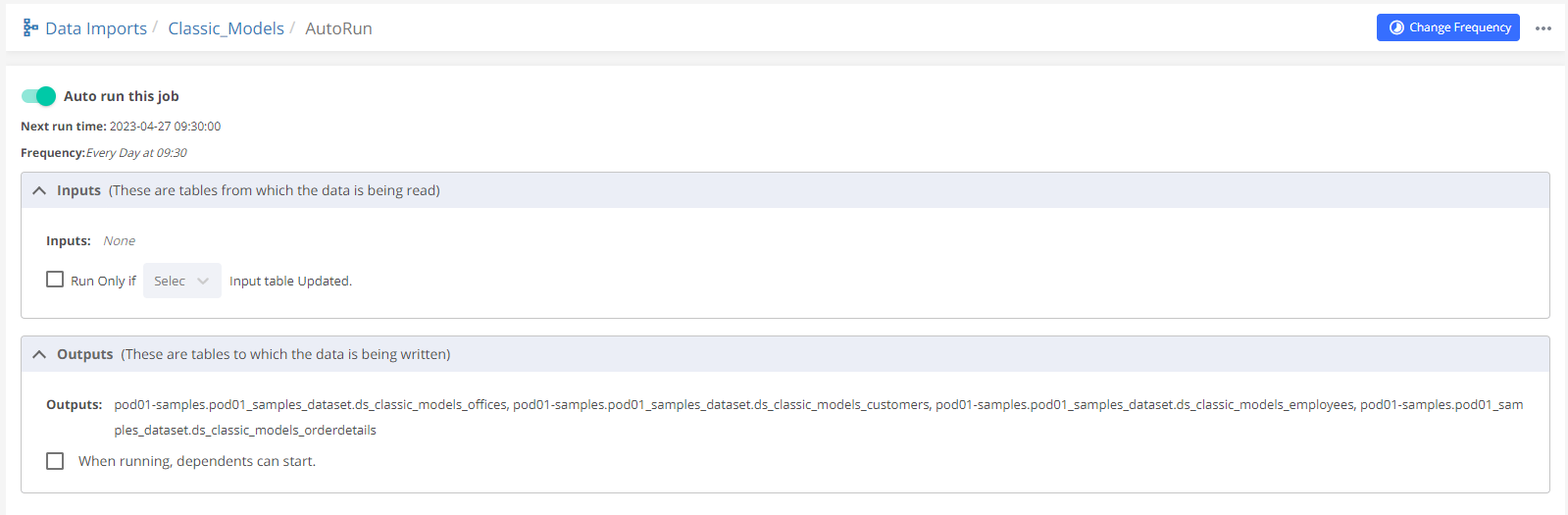
There are INPUTS, OUTPUTS, and other options on the auto-run page.
INPUTS - It will be None since the data is not being taken from any warehouse table. Keep the ‘Run Only If' button unchecked since there is no input table.
OUTPUTS - It will show all the tables into which data is being written from this data import.
When running, dependents can start Let's understand this feature with the help of an example: There are 10 tables in the data import, and a few of them take longer to complete. In this case, if dependents are scheduled to run in real time. Then that particular data import takes time because of very big tables and the pipeline will get delayed. So, if the option ‘When running, dependent can start' is selected then the dependents will start running even when the long-running table in the data import is still in the running state which will keep the dependents up to date.
But, if it's not selected then the dependents have to wait till all the source tables are ingested in the data import. But in this case, there is a chance that a few dependents will not be updated with the latest data.
If the ‘When running, dependent can start' is selected and the long-running table is under complete ingestion mode, then if the dependent starts running at the same time the dependent job will fail.
NOTE: In a data import if any tables take a longer time to ingest then creating another data import for the long-running tables is a good practice. So, there won't be any dependency on the very big tables and dependents will run on time.
2. Scheduling Dependent Tables from the Data Import
Once raw data from the Data import is ingested in the warehouse, then various tables can be created from those datasets after transforming, cleaning, and joining the tables.
Let's see how to schedule these transformed tables efficiently.
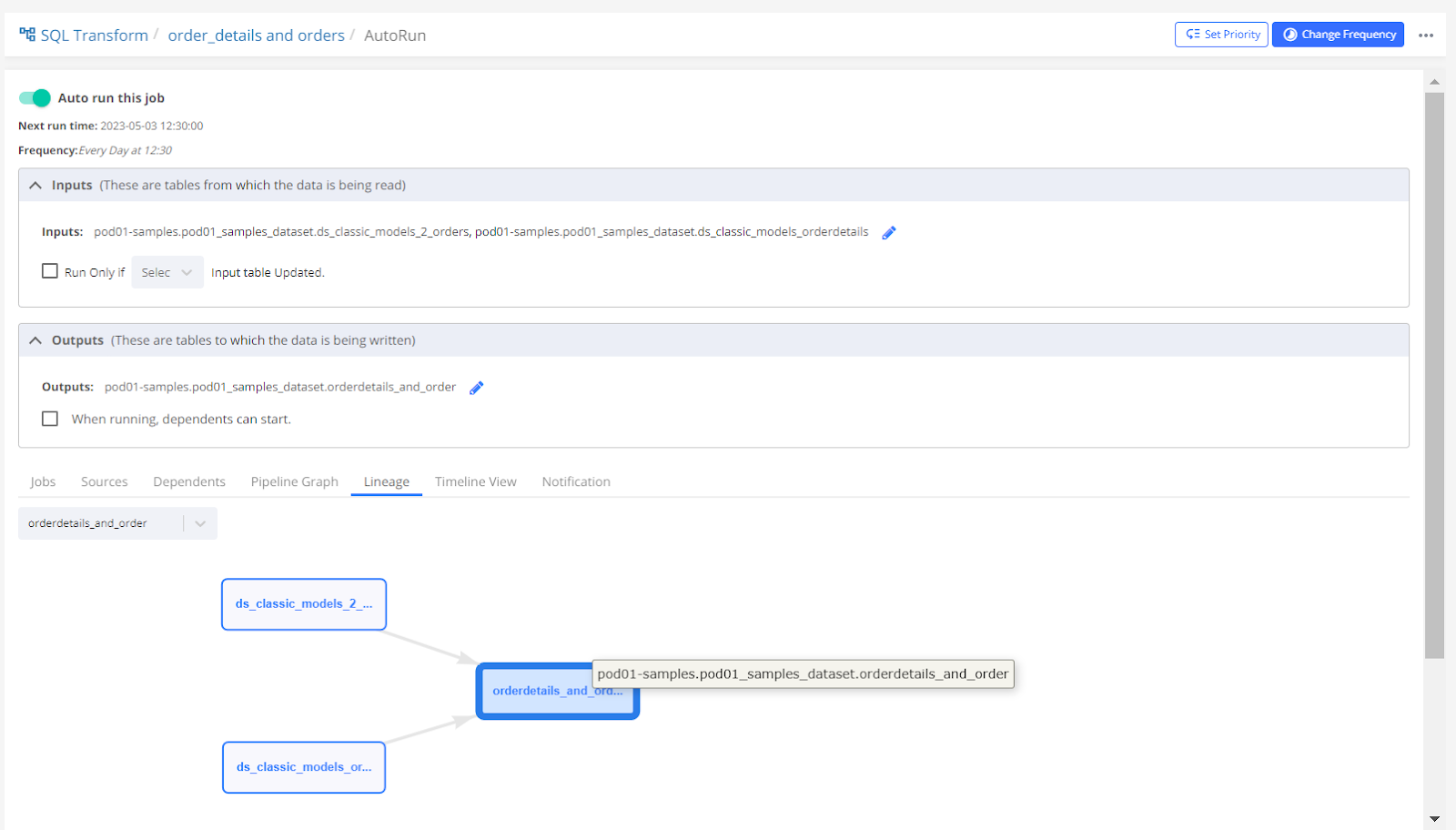
Table name - orderdetails_and_order
This table is created from the tables ‘ds_Classic_Models_orderdetails' (Data Import = Classic_Models) and ‘ds_Classic_Models_2_orders' ( Data Import = Classic_Models_2)
The data import Classic_Models is scheduled at 09:30 hrs and Classic_Models_2 is scheduled at 11:30 hrs.
2.1) Scheduling SQL Transform -
The job is scheduled at 12:30 hrs. The input and output tables are automatically mapped on the Auto-Run page.
INPUT- The tables from where data is being read.
OUTPUT- The tables into which data is being written.
The lineage chart below shows the flow of data from input tables (‘ds_Classic_Models_orderdetails', ‘ds_Classic_Models_2_orders' ) to the output table ( ‘orderdetails_and_order' )
CASE 1
The ‘Run Only If' option is not selected in this case.
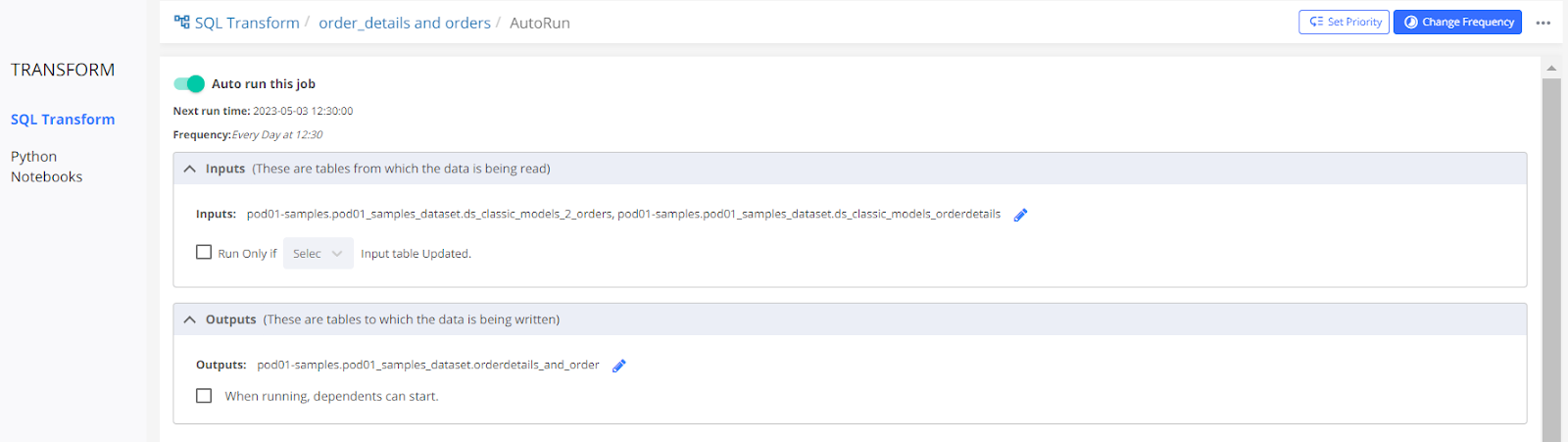
The scheduled job for the table will run at the time it is scheduled (i.e. 12:30 hrs) irrespective of the status of the dependent tables. If by any chance the source tables are dropped and fail while creating again, then this scheduled job will fail.
If the input and output tables are scheduled at the same time and the Input tables are updated every time with complete fetch (DROP AND CREATE COMMAND), then the job for the output table will fail because the input table is dropped while the job is running. Whereas, if the input table is updated incrementally (INSERT INTO COMMAND), the job for the output table won't fail but it won't have all the data from the input table.
Note- It's a good practice to keep the scheduled time of the dependent job after the source job is completed.
CASE 2
The ‘Run Only If' option is checked with the ‘Any' input table updated.
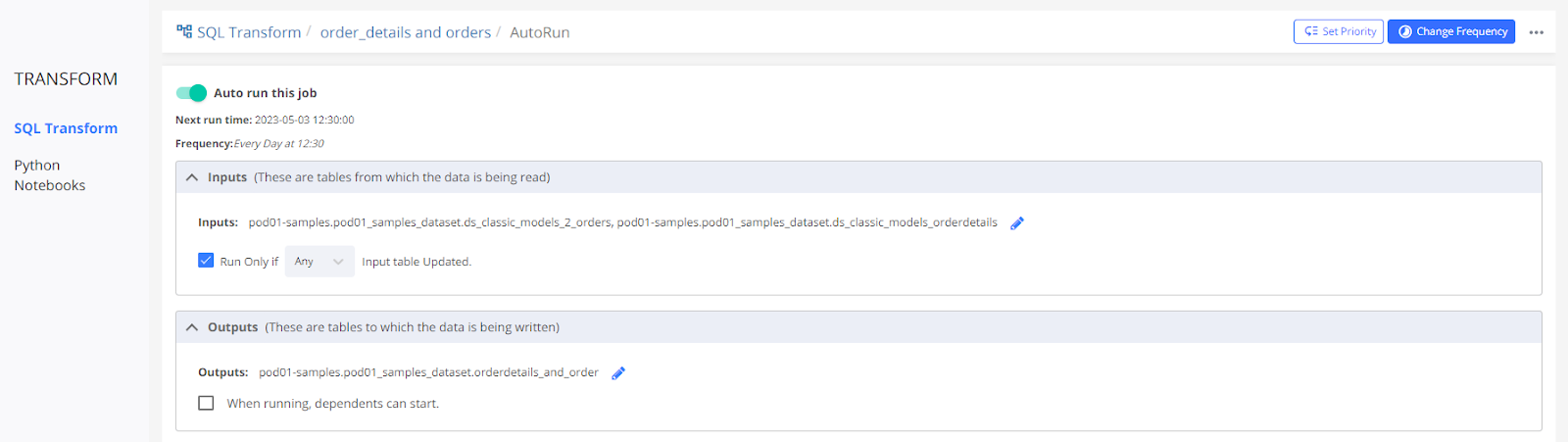
In this case, the scheduled job will run only if any of the input tables are updated, but if none of the input tables are updated then the scheduled job won't start. It is useful when the input tables are updated at different times and you want to keep the output table updated as soon as any input table is updated. Schedule the time after every input table is updated and keep the option as ‘Any'. In this case, the job will run only once at 12:30 hrs and the output tables will be updated at that time only.
Note- 1) If the input tables are getting updated at different times and you want the output table to be updated as soon as any input table is updated then schedule the job after every input table is updated. In this case, scheduling at 09:40 hrs and 11:40 hrs will be the best because the output table will be updated most of the time.
2) Even if the job is scheduled at 09:00 hrs, the job will run only after the data import scheduled at 09:30 hr is finished.
CASE 3
The ‘Run Only If' option is checked with the ‘All' table updated.
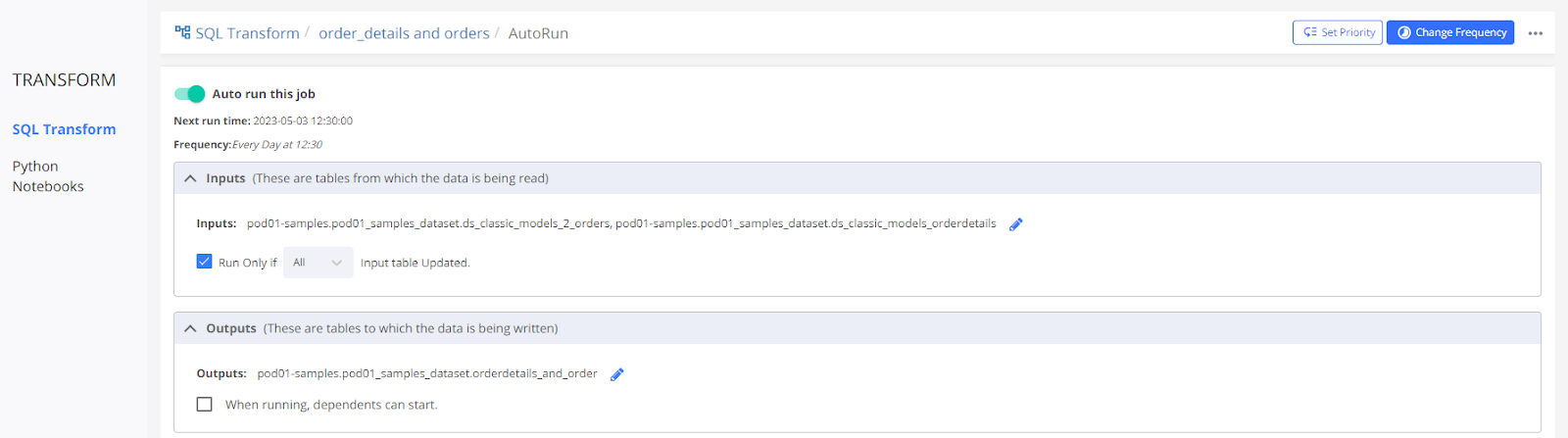
It means that the job will run only when all the input tables are updated. Here the input tables are updated at 09:30 and 11:30 but the job is scheduled at 12:30. The job will start at its scheduled time i.e. 12:30 hrs because both the input tables are updated.
Note- If the job is scheduled at 09:00 hrs, the job will start but will be in a queued state until both the dependent tables are updated. The second dependent table is scheduled at 11:30, once that dependent table is updated this job will be running.
CASE 4
When running, dependents can start. The dependent of this SQL Transform is the model. If this option is selected, then the dependent model job can run simultaneously. If the table is updated with complete fetch ( DROP and CREATE TABLE) then the model job will fail. If the table is updated with incremental fetch ( INSERT INTO) then the dependent job will run fine but with partial data.
NOTE- In the case where the dependent is a Model job, it's better to keep it unselected.
3. Creating Model
Model ‘orderdetails_order' is created on the table ‘orderdetails_and_order' which is created in the previous step.
Scheduling Model-
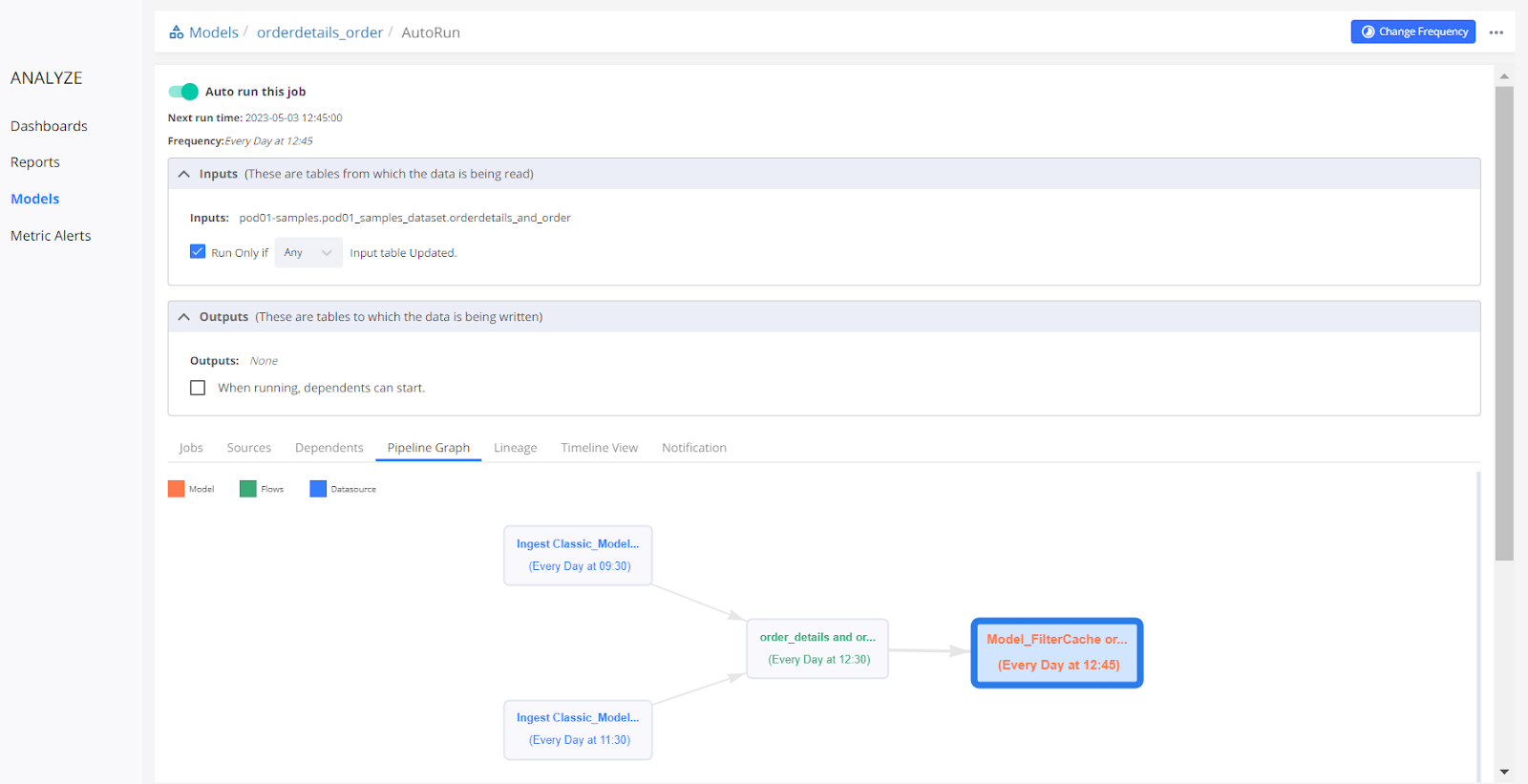
The model has only 1 dependent table which is present in the input table which gets updated at 12:30 hrs. Here ‘Run only if' is selected with the ‘Any' table updated.
A Pipeline Graph is also shown which shows the flow of data till the model.
CASE 1
‘Run Only If' is unchecked- The model scheduled job will run without considering the status of input tables.
If the input table is getting created using the ‘DROP and CREATE TABLE' command and if by any chance the input table job fails, then the input table will not be present in the warehouse. In this case, the model job starts running at its scheduled time and the job will fail as the input table is not present.
If the input table is getting updated using the ‘INSERT' query then there should be sufficient time gap between the model job and input table, because the model job should run only once the input table is updated completely. If both the jobs run at the same time then the model will get updated with partial data from the table.
Note- In this case, it's better to select the ‘Run Only If' option as it'll make sure that the model job will start running after the input table is updated.
CASE 2
‘Run Only If' is checked- The model job will run based on the updated status of the input table. In this case, there is only 1 input table so ‘Any' and ‘All' both will work in the same way.
The model job will run only when the input table is updated and is present in the warehouse.
4. Creating Reports using Models-
There is no need to schedule an Auto-Run for Reports if these are added to the Dashboard.
5. Creating Dashboard -
Add all the reports in the dashboard and turn on auto-run.
All the input tables will be automatically mapped to the INPUT section, whereas the OUTPUT section will be None since no output table is being created.
The dashboard is scheduled at 13:00 hr.

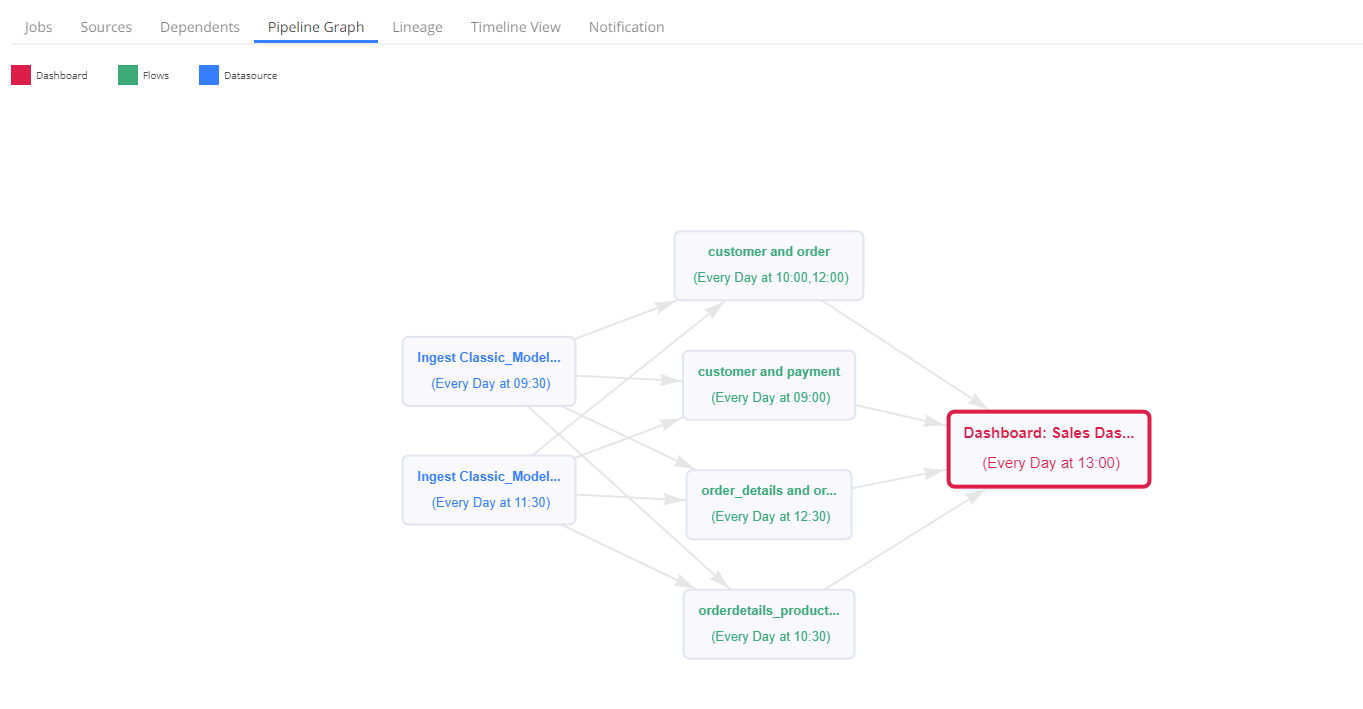
Pipeline Graph for the dashboard-
There are 2 data imports (blue colored) having 4 datasets in each data import. From those 2 data imports, 4 transformed tables(green colored) are created taking 1 dataset from each data import.
On top of these 4 tables, models and reports are created, which are then added to the dashboard (Red colored)
CASE 1
‘Run Only If' is not selected -
The dashboard will run at its scheduled time (i.e. 13:00 hr) irrespective of the status of the input tables.
Note- If any of the input tables is deleted then the dashboard job will fail.
CASE 2
‘Run Only If' is selected with ‘Any' table is updated -
In this case, the scheduled job will run only if any of the input tables are updated, but if none of the input tables are updated then the scheduled job won't start.
CASE 3
The ‘Run Only If' option is checked with the ‘All' table updated.
It means that the job will run only when all the input tables are updated.
Frequently Asked Questions FAQs- How to build an efficient data pipeline with Sprinkle
How do you build a data pipeline step by step?
To build a data pipeline step by step, one can start by identifying the data sources, defining the data transformation requirements, selecting the appropriate tools and technologies, designing the pipeline architecture, implementing the pipeline, testing and validating the pipeline, and finally, deploying and monitoring the pipeline.
How can one improve pipeline efficiency?
Pipeline efficiency can be improved by optimizing data processing, minimizing data movement, leveraging parallel processing, implementing caching mechanisms, and continuously monitoring and optimizing the pipeline.
What techniques can be used to make data pipelines more efficient?
Techniques such as data partitioning, batch processing, stream processing, and incremental updates can be used to make data pipelines more efficient.
What are some methods for optimizing a data pipeline?
Methods for optimizing a data pipeline include load balancing, resource allocation, data compression, and implementing error handling and fault tolerance mechanisms.
What are some common pipeline optimization techniques?
Common pipeline optimization techniques include caching, parallelization, data compression, and load balancing.
How can one increase the speed of a data pipeline?
The speed of a data pipeline can be increased by leveraging distributed processing, implementing caching mechanisms, and optimizing data transfer protocols.
What is the definition of pipeline efficiency?
Pipeline efficiency is defined as the ratio of the desired output to the resources (time, computing power, storage, etc.) used to generate that output.
How can one reduce the CI (Continuous Integration) time of a pipeline?
Continuous Integration (CI) time can be reduced by implementing parallel processing, caching, and optimizing the pipeline's configuration and deployment processes.
Which type of pipeline is generally faster?
Generally, a batch-based pipeline is faster than a real-time streaming pipeline, as batch processing can leverage more efficient data processing techniques.
Why are data pipelines considered efficient?
Data pipelines are considered efficient because they automate the data ingestion, transformation, and delivery processes, reducing manual effort and improving overall data processing speed and reliability.







